- Beurteilung eines Klassifikators
-
Bei einer Klassifizierung werden Objekte anhand von bestimmten Merkmalen durch einen Klassifikator in verschiedene Klassen eingeordnet. Der Klassifikator macht dabei im Allgemeinen Fehler, ordnet also in manchen Fällen ein Objekt einer falschen Klasse zu. Aus der relativen Häufigkeit dieser Fehler lassen sich quantitative Maße zur Beurteilung eines Klassifikators ableiten.
Häufig ist die Klassifikation binärer Natur, d. h. es gibt nur zwei mögliche Klassen. Die hier diskutierten Gütemaße beziehen sich ausschließlich auf diesen Fall. Solche binäre Klassifikationen werden häufig in Form einer Ja/Nein-Frage formuliert: Leidet ein Patient an einer bestimmten Krankheit oder nicht? Ist ein Feuer ausgebrochen oder nicht? Nähert sich ein feindliches Flugzeug oder nicht? Bei Klassifikationen dieser Art gibt es zwei mögliche Arten von Fehlern: Ein Objekt wird der ersten Klasse zugeordnet, obwohl es der zweiten angehört, oder umgekehrt. Die hier beschriebenen Kennwerte bieten dann eine Möglichkeit, die Zuverlässigkeit des zugehörigen Klassifikators (Diagnoseverfahren, Feuermelder, Fliegerradar) zu beurteilen.
Ja-Nein-Klassifikationen weisen Ähnlichkeiten zu statistischen Tests auf, bei denen zwischen einer Nullhypothese und einer Alternativhypothese entschieden wird.
Inhaltsverzeichnis
Wahrheitsmatrix: Richtige und falsche Klassifikationen
 Ein Test soll kranke und gesunde Menschen voneinander unterscheiden. Jeder Mensch wird durch einen Punkt dargestellt, der links (krank) bzw. rechts (gesund) der schwarzen Linie liegt. Die Punkte im Oval sind die von dem Test als krank klassifizierten Menschen. Die Farben entsprechen den vier Fällen, die bei dieser Klassifikation auftreten können.
Ein Test soll kranke und gesunde Menschen voneinander unterscheiden. Jeder Mensch wird durch einen Punkt dargestellt, der links (krank) bzw. rechts (gesund) der schwarzen Linie liegt. Die Punkte im Oval sind die von dem Test als krank klassifizierten Menschen. Die Farben entsprechen den vier Fällen, die bei dieser Klassifikation auftreten können.
Um einen Klassifikator zu bewerten, muss man ihn in einer Reihe von Fällen anwenden, bei denen man zumindest im Nachhinein Kenntnis über die „wahre“ Klasse der jeweiligen Objekte hat. Ein Beispiel für so einen Fall ist ein medizinischer Labortest, mit dem festgestellt werden soll, ob eine Person eine bestimmte Krankheit hat. Später wird durch aufwändigere Untersuchungen festgestellt, ob die Person tatsächlich an dieser Krankheit leidet. Der Test stellt einen Klassifikator dar, der die Personen in die Kategorien „krank“ und „gesund“ einordnet. Da es sich um eine Ja/Nein-Frage handelt, sagt man auch, der Test fällt positiv (Einordnung „krank“) oder negativ (Einordnung „gesund“) aus. Um zu beurteilen, wie gut geeignet der Labortest für die Diagnose der Krankheit ist, wird nun bei jedem Patient dessen tatsächlicher Gesundheitszustand mit dem Ergebnis des Tests verglichen. Dabei können vier mögliche Fälle auftreten:
- Richtig positiv: Der Patient ist krank, und der Test hat dies richtig angezeigt.
- Falsch negativ: Der Patient ist krank, aber der Test hat ihn fälschlicherweise als gesund eingestuft.
- Falsch positiv: Der Patient ist gesund, aber der Test hat ihn fälschlicherweise als krank eingestuft.
- Richtig negativ: Der Patient ist gesund, und der Test hat dies richtig angezeigt.
Im ersten und letzten Fall war die Diagnose also richtig, in den anderen beiden Fällen liegt ein Fehler vor. Die vier Fälle werden in verschiedenen Kontexten auch anders benannt. So sind auch die englischen Begriffe true positive, false positive, false negative und true negative gebräuchlich. Im Rahmen der Signalentdeckungstheorie werden richtig positive Fälle auch als hit, falsch negative Fälle als miss und richtig negative Fälle als correct rejection bezeichnet.
Es wird nun gezählt, wie häufig jede der vier möglichen Kombinationen von Testergebnis (ermittelte Klasse) und Gesundheitszustand (tatsächliche Klasse) vorgekommen ist. Diese Häufigkeiten werden in eine sogenannte Wahrheitsmatrix (auch Konfusionsmatrix genannt) eingetragen:
Person ist krank (rp+fn) Person ist gesund (fp+rn) Test positiv (rp+fp) richtig positiv (rp) falsch positiv (fp) Test negativ (fn+rn) falsch negativ (fn) richtig negativ (rn) Diese Matrix ist ein einfacher Spezialfall einer Kontingenztafel mit zwei nominalen Variablen - dem Urteil des Klassifikators und der tatsächlichen Klasse. Sie kann auch für Klassifikationen mit mehr als zwei Klassen eingesetzt werden, dann wird bei N Klassen aus einer 2×2-Matrix eine N×N-Matrix.
Statistische Gütekriterien der Klassifikation
Durch Berechnung verschiedener relativer Häufigkeiten können aus den Werten der Wahrheitsmatrix nun Kenngrößen zur Beurteilung des Klassifikator berechnet werden. Diese können auch als Schätzungen der bedingte Wahrscheinlichkeiten für das Eintreten des entsprechenden Ereignisses interpretiert werden. Die Maße unterscheiden sich hinsichtlich der Grundgesamtheit, auf die sich die relativen Häufigkeiten beziehen: So können etwa nur alle die Fälle in Betracht gezogen werden, in denen die positive bzw. negative Kategorie tatsächlich vorliegt (Summe über die Einträge einer Spalte der Wahrheitsmatrix), oder man betrachtet die Menge aller Objekte, die als positiv bzw. negativ klassifiziert werden (Summe über die Einträge einer Zeile der Wahrheitsmatrix). Diese Wahl hat gravierende Auswirkungen auf die berechneten Werte, insbesondere dann, wenn eine der beiden Klassen insgesamt viel häufiger vorkommt als die andere. In den nachfolgenden Bildern sind die jeweils betrachteten Grundgesamtheiten durch rote und grüne Farbe gekennzeichnet, während die Objekte in den grauen Bereichen nicht zur Berechnung der jeweiligen Maße heran gezogen werden.
Sensitivität und Falsch-Negativ-Rate
 Sensitivität (grün) und Falsch-Negativ-Rate (rot)
Sensitivität (grün) und Falsch-Negativ-Rate (rot)Die Sensitivität (auch Richtig-Positiv-Rate, Empfindlichkeit oder Trefferquote; englisch sensitivity, true positive rate, recall oder hit rate) gibt den Anteil der korrekt als positiv klassifizierten Objekte an der Gesamtheit der tatsächlich positiven Objekte an. Beispielsweise entspricht Sensitivität bei einer medizinischen Diagnose dem Anteil an tatsächlich Kranken, bei denen die Krankheit auch erkannt wurde.
Die Sensitivität entspricht der geschätzten bedingten Wahrscheinlichkeit
 .
.
Entsprechend gibt die Falsch-Negativ-Rate (englisch false negative rate oder miss rate) den Anteil der fälschlich als negativ klassifizierten Objekte an, die in Wirklichkeit positiv sind, also im Beispiel die tatsächlich Kranken, die aber als gesund diagnostiziert werden.
Die Falsch-Negativ-Rate entspricht der geschätzten bedingten Wahrscheinlichkeit
 .
.
Da sich beide Maße auf den Fall beziehen, dass in Wirklichkeit die positive Kategorie vorliegt (erste Spalte der Wahrheitsmatrix), addieren sich die Sensitivität und die Falsch-Negativ-Rate zu 1 bzw. 100 %.
Spezifität und Falsch-Positiv-Rate
 Spezifität (grün) und Falsch-Positiv-Rate (rot)
Spezifität (grün) und Falsch-Positiv-Rate (rot)Die Spezifität (auch Richtig-Negativ-Rate oder kennzeichnende Eigenschaft; englisch: specificity, true negative rate oder correct rejection rate) gibt den Anteil der korrekt als negativ klassifizierten Objekte an der Gesamtheit der in Wirklichkeit negativen Objekte an. Beispielsweise gibt die Spezifität bei einer medizinischen Diagnose den Anteil der Gesunden an, bei denen auch festgestellt wurde, dass keine Krankheit vorliegt.
Die Spezifität entspricht der geschätzten bedingten Wahrscheinlichkeit
 .
.
Entsprechend gibt die Falsch-Positiv-Rate (auch Ausfallrate; englisch fallout oder false positive rate) den Anteil der fälschlich als positiv klassifizierten Objekte an, die in Wirklichkeit negativ sind. Im Beispiel würde dann ein tatsächlich Gesunder zu Unrecht als krank diagnostiziert. Es wird also die Wahrscheinlichkeit für einen Fehlalarm angegeben.
Die Falsch-Positiv-Rate entspricht der geschätzten bedingten Wahrscheinlichkeit
 .
.
Da sich beide Maße auf den Fall beziehen, dass in Wirklichkeit die negative Kategorie vorliegt (zweite Spalte der Wahrheitsmatrix), addieren sich die Spezifität und die Falsch-Positiv-Rate zu 1 bzw. 100 %.
Positiver und negativer Vorhersagewert
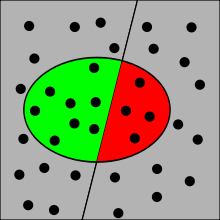 Positiver Vorhersagewert (grün)
Positiver Vorhersagewert (grün)Der positive Vorhersagewert (auch Relevanz, Wirksamkeit, Genauigkeit, positiver prädiktiver Wert; englisch: precision oder positive predictive value; Abkürzung: PPV) gibt den Anteil der korrekt als positiv erkannten Ergebnisse an der Gesamtheit der als positiv erkannten Ergebnisse an (erste Zeile der Wahrheitsmatrix). Beispielsweise gibt der positive Vorhersagewert einer medizinischen Diagnose an, wie viele Personen, bei denen die Krankheit festgestellt wurde, auch tatsächlich krank sind.
Der positive Vorhersagewert entspricht der geschätzten bedingten Wahrscheinlichkeit
 .
.
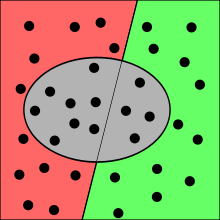 Negativer Vorhersagewert (grün)
Negativer Vorhersagewert (grün)Entsprechend gibt der negative Vorhersagewert (auch Segreganz oder Trennfähigkeit; englisch: negative predictive value; Abkürzung: NPV) den Anteil der korrekt als negativ erkannten Ergebnisse an der Gesamtheit der als negativ erkannten Ergebnisse an (zweite Zeile der Wahrheitsmatrix). Im Beispiele entspricht das dem Anteil der tatsächlich gesunden Personen, bei denen die Krankheit nicht festgestellt wurde.
Der negative Vorhersagewert entspricht der geschätzten bedingten Wahrscheinlichkeit
Anderes als die anderen Paare von Gütemaßen addieren sich der negative und der positive Vorhersagewert nicht zu 1 bzw. 100 %, da jeweils von unterschiedlichen Fällen ausgegangen wird (tatsächlich positiv bzw. tatsächlich negativ, d. h. unterschiedliche Spalten der Wahrheitsmatrix).
Es ist zu beachten, dass der positive und negative Vorhersagewert in einem gegebenen Kollektiv (z. B. Gesamtbevölkerung) nur dann aussagekräftig ist, wenn die Häufigkeit der positiven Fälle, etwa die Prävalenz der betreffenden Erkrankung, im Kollektiv und in der erhobenen Gruppe übereinstimmt. Beispiel: Wurden zur Bestimmung des positiven Vorhersagewerts 100 HIV-Patienten und 100 gesunde Kontrollpatienten untersucht, so ist der Anteil an HIV-Patienten in dieser Gruppe (50 %) weit von der tatsächlichen Prävalenz von HIV in der Gesamtbevölkerung (0,08 %) entfernt (siehe dazu auch das unten genannte Zahlenbeispiel). Die Angabe von Vorhersagewerten, die in einem solchen, selektiven Kollektiv erhoben wurden, ist nicht zulässig und irreführend. In solchen Fällen ist es sinnvoll, die likelihood ratio (LR) (positive LR = Sensitivität/[1-Spezifität]; negative LR = [1-Sensitivität]/Spezifität) anzugeben (nicht zu verwechseln mit dem Likelihood-Quotienten-Test).
Korrekt- und Falschklassifikationsrate
Korrekt- (grün) und Falschklassifikationsrate (rot)Die Falschklassifikationsrate (auch Größe des Klassifikationsfehlers) gibt den Anteil der aller Objekte an, die falsch klassifiziert werden. Der restliche Anteil entspricht der Korrektklassifikationsrate (auch Vertrauenswahrscheinlichkeit). Im Beispiel der Diagnose wäre die Falschklassifikationsrate der Anteil an falsch positiven und falsch negativen Diagnosen an der Gesamtzahl der Diagnosen, die Korrektklassifikationsrate hingegen der Anteil der richtig positiven und richtig negativen Diagnosen.
Die Korrektklassifikationsrate entspricht der geschätzten Wahrscheinlichkeit
 .
.
und die Falschklassifikationsrate der geschätzten Wahrscheinlichkeit
 .
.
Die Korrekt- und die Falschklassifikationsrate addieren sich entsprechend zu 1 oder 100 %.
Kombinierte Maße
Da sich die verschiedenen Gütemaße gegenseitig beeinflussen (siehe Abschnitt Probleme), wurden verschiedene kombinierte Maße vorgeschlagen, die eine Beurteilung der Güte mit einer einzigen Kennzahl erlauben. Die im Folgenden vorgestellten Maße wurden im Kontext des Information Retrieval entwickelt (siehe Anwendung im Information Retrieval).
Das F-Maß kombiniert Genauigkeit (precision) und Trefferquote (recall) mittels des gewichteten harmonischen Mittels:
Neben diesem auch als F1 bezeichneten Maß, bei dem Genauigkeit und Trefferquote gleich gewichtet sind, gibt es auch andere Gewichtungen. Der Allgemeinfall ist das Maß Fα (für positive Werte von α):
Beispielsweise gewichtet F2 die Trefferquote doppelt so groß wie die Genauigkeit und F0.5 die Genauigkeit doppelt so hoch wie die Trefferquote.
Das Effektivitätsmaß (E) entspricht ebenfalls dem gewichteten harmonischen Mittel. Es wurde 1979 von van Rijsbergen eingeführt. Die Effektivität liegt zwischen 0 (beste Effektivität) und 1 (schlechte Effektivität). Für einen Parameterwert von α = 0 ist E äquivalent zur Trefferquote, für einen Parameterwert von α = 1 äquivalent zur Genauigkeit.

Probleme
Gegenseitige Beeinflussungen
Es ist nicht möglich, alle Gütekriterien unabhängig voneinander zu optimieren. Insbesondere sind die Sensitivität und die Spezifität negativ miteinander korreliert. Zur Veranschaulichung dieser Zusammenhänge ist es hilfreich, die Extremfälle zu betrachten:
- Wenn eine Diagnose fast alle Patienten als krank klassifiziert (liberale Diagnose), ist die Sensitivität maximal, denn es werden die meisten Kranken auch als solche erkannt. Allerdings wird gleichzeitig auch die Falsch-Positiv-Rate maximal, da auch fast alle Gesunden als krank eingestuft werden. Die Diagnose hat also eine sehr geringe Spezifität.
- Wird hingegen fast niemand als krank eingestuft (konservative Diagnose), ist umgekehrt die Spezifität maximal, allerdings auf Kosten einer geringen Sensitivität.
Wie konservativ oder liberal ein Klassifikator optimalerweise sein sollte, hängt vom konkreten Anwendungsfall ab, insbesondere davon, welche der Fehlklassifikation die schwerwiegenderen Folgen hat. Bei der Diagnose einer schlimmen Krankheit oder sicherheitsrelevanten Anwendungen wie einem Feueralarm ist es beispielsweise wichtig, dass kein Fall unentdeckt bleibt. Bei einer Recherche durch eine Suchmaschine hingegen kann es wichtiger sein, möglichst wenige Resultate zu bekommen, die für die Suche irrelevant sind, also falsch positive Resultate darstellen. Die Risiken der verschiedenen Fehlklassifikationen lassen sich zur Bewertung eines Klassifikators in einer Kostenmatrix angeben, mit der die Wahrheitsmatrix gewichtet wird. Eine weitere Möglichkeit besteht in der Verwendung kombinierter Maße, bei denen sich eine entsprechende Gewichtung einstellen lässt.
Um die Auswirkungen verschieden konservativer Tests für ein konkretes Anwendungsbeispiel darzustellen, können sogenannte Receiver Operating Characteristic- oder ROC-Kurven erstellt werden, in denen die Sensitivität für verschiedene Tests gegen die Falsch-Positiv-Rate aufgetragen wird. Im Rahmen der Signalentdeckungstheorie spricht man auch von einem verschieden konservativ gesetzten Kriterium.
Seltene Positiv-Fälle
Darüber hinaus wird auch ein extremes Ungleichgewicht zwischen tatsächlich positiv und negativen Fällen die Kenngrößen verfälschen, wie es etwa bei seltenen Krankheiten der Fall ist. Ist beispielsweise die Anzahl der an einem Test teilnehmenden Kranken erheblich geringer als die der Gesunden, so führt dies im allgemeinen zu einem geringen Wert im positiven Vorhersagewert (siehe dazu das unten angeführte Zahlenbeispiel). Daher sollte in diesem Fall alternativ zu den Vorhersagewerten die likelihood ratio angegeben werden.
Dieser Zusammenhang ist bei verschiedenen Labortests zu bedenken: Preiswerte Screening-Tests werden so justiert, dass eine möglichst kleine Anzahl falsch negativer Ergebnisse vorliegt. Die produzierten falsch positiven Testergebnisse werden anschließend durch einen (teureren) Bestätigungstest identifiziert. Für schwerwiegende Erkrankungen sollte immer ein Bestätigungstest durchgeführt werden. Dieses Vorgehen ist für die Bestimmung von HIV sogar gefordert.
Unvollständige Wahrheitsmatrix
Ein weiteres Problem bei der Beurteilung eines Klassifikators besteht darin, dass häufig nicht die gesamte Wahrheitsmatrix ausgefüllt werden kann. Insbesondere ist oft die Falsch-Negativ-Rate nicht bekannt, etwa wenn bei Patienten, die eine negative Diagnose erhalten, keine weiteren Tests durchgeführt werden und eine Krankheit unerkannt bleibt, oder wenn ein eigentlich relevantes Dokument bei einer Recherche nicht gefunden wird, weil es nicht als relevant klassifiziert wurde. In diesem Fall können nur die als positiv klassifizierten Ergebnisse ausgewertet werden, d. h. es kann nur der positive Vorhersagewert berechnet werden (siehe dazu auch das unten angeführte Zahlenbeispiel). Mögliche Lösungen für dieses Problem werden im Abschnitt Anwendung im Information Retrieval besprochen.
Klassifikationsbewertung und statistische Testtheorie
Binäre Klassifikation Statistischer Test Ziel Auf Basis einer Stichprobe werden Beobachtungen (Objekte) einer der beiden Klassen zugeordnet. Mittels einer Zufallsstichprobe werden zwei sich ausschliessende Hypothesen (Null- und Alternativhypothese) über die Grundgesamtheit geprüft. Vorgehen Der Klassifikator ist eine aus der Stichprobe geschätzte Regressionsfunktion mit zwei möglichen Ergebniswerten. Der Prüfwert wird mittels einer Teststatistik aus der Zufallsstichprobe berechnet und mit kritischen Werten, die aus der Verteilung der Teststatistik berechnet werden, verglichen. Ergebnis Für eine Beobachtung wird eine Klassenzugehörigkeit vorhergesagt. Aufgrund des Vergleiches von Prüfwert und kritischen Werten, kann die Alternativhypothese angenommen oder verworfen werden. Fehler Die Qualität eines Klassifikators wird mit der Falschklassifikationsrate (falsch positiv und falsch negativ) im Nachhinein beurteilt. Vor der Testdurchführung wird die Größe des Fehlers 1. Art (fälschlich Annahme der Alternativhypothese) festgelegt. Daraus werden die kritischen Werte berechnet. Der Fehler 2. Art (fälschlich Ablehnung der Alternativhypothese) ist immer unbekannt bei der Testdurchführung. Klassifikationsbewertung zur Beurteilung der Qualität statistischer Tests
Mit Hilfe der Klassifikationsbewertung kann die Qualität eines statistischen Test beurteilt werden:
- Generiert man viele Stichproben unter Gültigkeit der Nullhypothese, so sollte die Annahmerate der Alternativhypothese dem Fehler 1. Art entsprechen. Aber bei komplizierten Tests kann man oft nur eine obere Grenze für den Fehler 1. Art angeben, so dass der „wahre“ Fehler 1. Art nur mit einer solchen Simulation abgeschätzt werden kann.
- Generiert man viele Stichproben unter Gültigkeit der Alternativhypothese, so ist die Ablehnungsrate der Alternativhypothese eine Schätzung des Fehlers 2. Art. Dies ist beispielsweise von Interesse, wenn man zwei Tests für einen Sachverhalt hat. Wenn die Alternativhypothese gilt dann bevorzugt man den Test der einen kleineren Fehler 2. Art hat.
Statistische Tests zur Beurteilung einer Klassifikation
Man kann statistische Tests einsetzen, um zu überprüfen, ob eine Klassifikation statistisch signifikant ist, d. h. ob bzgl. der Grundgesamtheit die Einschätzung des Klassifikators unabhängig von den tatsächlichen Klassen ist (Nullhypothese) oder signifikant mit ihnen korreliert (Alternativhypothese).
Im Fall von mehreren Klassen kann dafür der Chi-Quadrat-Unabhängigkeitstest verwendet werden. Dabei wird geprüft, ob die Einschätzung des Klassifikators unabhängig von den tatsächlichen Klassen ist oder signifikant mit ihnen korreliert. Die Stärke der Korrelation wird durch Kontingenzkoeffizienten abgeschätzt.
Im Fall einer binären Klassifikation wird der Vierfeldertest verwendet, ein Spezialfall des Chi-Quadrat-Unabhängigkeitstests. Hat man nur wenige Beobachtungswerte sollte der Exakte Fisher-Test verwendet werden. Die Stärke der Korrelation kann mit dem Phi-Koeffizient abgeschätzt werden.
Lehnt der Test die Nullhypothese ab, bedeutet es jedoch nicht, dass der Klassifikator gut ist. Es bedeutet nur, dass er besser ist als (zufälliges) Raten. Ein guter Klassifikator sollte auch eine möglichst hohe Korrelation aufweisen.
In Diettrich (1998) werden fünf Tests untersucht zum direkten Vergleich von Missklassifikationsraten von zwei unterschiedlichen Klassifikatoren: [1] ein einfacher Zweistichproben-t-Test für unabhängige Stichproben, ein Zweistichproben-t-Test für verbundene Stichproben, ein Zweistichproben-t-Test für verbundene Stichproben mit 10fach-Kreuzvalidierung, der McNemar-Test und ein Zweistichproben-t-Test für verbundene Stichproben mit 5fach-Kreuzvalidierung und modifizierter Varianzberechnung (5x2cv). Als Ergebnis der Untersuchung von Güte und Fehler 1. Art der fünf Tests ergibt sich, dass sich der 5x2cv Test am besten verhält, jedoch sehr rechenaufwendig ist. Der McNemar Test ist etwas schlechter als der 5x2cv Test, jedoch deutlich weniger rechenaufwendig.
Anwendung im Information Retrieval
Ein spezieller Anwendungsfall der hier beschriebenen Maße ist die Beurteilung der Güte von Treffermengen einer Recherche beim Information Retrieval. Dabei geht es um die Beurteilung, ob ein gefundenes Dokument, etwa beim Webmining durch Suchmaschinen, entsprechend eines definierten Kriteriums relevant ist. In diesem Zusammenhang sind die oben definierten Bezeichnungen Trefferquote (engl. ‚recall‘), Genauigkeit (engl. ‚precision‘) und Ausfallquote (engl. ‚fallout‘) gebräuchlich. Die Trefferquote gibt den Anteil der bei einer Suche gefundenen relevanten Dokumente, und damit die Vollständigkeit eines Suchergebnisses an. Die Genauigkeit beschreibt mit dem Anteil relevanter Dokumente an der Ergebnismenge die Genauigkeit eines Suchergebnisses. Der (seltener gebräuchliche) Ausfall bezeichnet den Anteil gefundener irrelevanter Dokumente an der Gesamtmenge aller irrelevanten Dokumente, er gibt also in negativer Weise an, wie gut irrelevante Dokumente im Suchergebnis vermieden werden. Statt als Maß können Trefferquote, Genauigkeit und Ausfall auch als Wahrscheinlichkeit interpretiert werden:
- Trefferquote ist die Wahrscheinlichkeit, mit der ein relevantes Dokument gefunden wird (Sensitivität).
- Genauigkeit ist die Wahrscheinlichkeit, mit der ein gefundenes Dokument relevant ist (Positiver Vorhersagewert, Spezifität).
- Ausfall ist die Wahrscheinlichkeit, mit der ein irrelevantes Dokument gefunden wird (Falsch-Positiv-Rate).
Eine gute Recherche sollte möglichst alle relevanten Dokumente finden (richtig positiv) und die nicht relevanten Dokumente nicht finden (richtig negativ). Wie oben beschrieben, hängen die verschiedenen Maße jedoch voneinander ab. Im Allgemeinen sinkt mit steigender Trefferrate die Genauigkeit (mehr irrelevante Ergebnisse). Umgekehrt sinkt mit steigender Genauigkeit (weniger irrelevante Ergebnisse) die Trefferrate (mehr relevante Dokumente die nicht gefunden werden). Je nach Anwendungsfall sind die unterschiedlichen Maße zur Beurteilung mehr oder weniger relevant. Bei einer Patentrecherche ist es beispielsweise wichtig, dass keine relevanten Patente unentdeckt bleiben, also sollte der Negative Vorhersagewert möglichst hoch sein. Bei anderen Recherchen ist es wichtiger, dass die Treffermenge wenig irrelevante Dokumente enthält, d. h. der Positive Vorhersagewert sollte möglichst hoch sein.
Im Kontext des Information Retrieval wurden auch die oben beschriebenen kombinierten Maße wie der F-Wert und die Effektivität eingeführt.
Genauigkeit-Trefferquote-Diagramm
Zur Einschätzung eines Retrieval-Verfahrens werden meist Trefferquote und Genauigkeit gemeinsam betrachtet. Dazu werden im so genannten Precision-Trefferquote-Diagramm (PR-Diagramm) für verschieden große Treffermengen zwischen den beiden Extremen Genauigkeit auf der Ordinate und Trefferquote auf der Abszisse eingetragen. Dies ist vor allem leicht bei Verfahren möglich, deren Treffermenge durch einen Parameter gesteuert werden kann. Dieses Diagramm erfüllt einen ähnlichen Zweck wie die oben beschriebene ROC-Kurve, die man in diesem Zusammenhang auch als Trefferquote-Fallout-Diagramm bezeichnet.
Der (höchste) Wert im Diagramm, an dem der Precision-Wert gleich dem Treffer-Wert ist – also der Schnittpunkt des Genauigkeit-Trefferquote-Diagramms mit der Identitätsfunktion – wird der Genauigkeit-Trefferquote-Breakeven-Punkt genannt. Da beide Werte voneinander abhängen, wird auch oft der eine bei fixiertem anderen Wert genannt. Eine Interpolation zwischen den Punkten ist allerdings nicht zulässig, es handelt sich um diskrete Punkte, deren Zwischenräume nicht definiert sind.
Beispiel
In einer Datenbank mit 36 Dokumenten sind zu einer Suchanfrage 20 Dokumente relevant und 16 nicht relevant. Eine Suche liefert 12 Dokumente, von denen tatsächlich 8 relevant sind.
Relevant Nicht relevant Gefunden 8 4 Nicht gefunden 12 12 Trefferquote und Precision für die konkrete Suche ergeben sich aus den Werten der Konfusionsmatrix.
- Genauigkeit: 8⁄(8+4) = 8⁄12 = 2⁄3 ≈ 0,67
- Trefferquote: 8⁄(8+12) = 8⁄20 = 2⁄5 = 0,4
- Fallout: 4⁄(4+12) = 4⁄16 = 1⁄4 = 0,25
Praxis und Probleme
Ein Problem bei der Berechnung der Trefferquote ist die Tatsache, dass man nur selten weiß, wie viele relevante Dokumente insgesamt existieren und nicht gefunden wurden (Problem der unvollständigen Wahrheitsmatrix). Bei größeren Datenbanken, bei denen die Berechnung der absoluten Trefferquote besonders schwierig ist, wird deswegen mit der relativen Trefferquote gearbeitet. Dabei wird die gleiche Suche mit mehreren Suchmaschinen durchgeführt und die jeweils neuen relevanten Treffer zu den nicht gefundenen relevanten Dokumenten hinzu addiert. Mit der Rückfangmethode kann abgeschätzt werden, wie viele relevante Dokumente insgesamt existieren.
Problematisch ist auch, dass zur Bestimmung von Trefferquote und Genauigkeit die Relevanz eines Dokumentes als Wahrheitswert (ja/nein) bekannt sein muss. In der Praxis ist jedoch oft die Subjektive Relevanz von Bedeutung. Auch für gerankte Treffermengen ist die Angabe von Trefferquote und Precision oft nicht ausreichend, da es nicht nur darauf ankommt, ob ein relevantes Dokument gefunden wird, sondern auch ob es im Vergleich zu nicht relevanten Dokumenten genügend hoch gerankt wird. Bei sehr unterschiedlich großen Treffermengen kann die Angabe durchschnittlicher Werte für Trefferquote und Genauigkeit irreführend sein.
Weitere Anwendungsbeispiele
HIV in der BRD
Das Ziel eines HIV-Tests sollte die möglichst sichere Erkennung eines Infizierten sein. Aber welche Konsequenzen ein falsch positiver Test haben kann, zeigt das Beispiel eines Menschen, der sich auf HIV testen lässt und dann aufgrund eines falsch-positiven Ergebnisses Suizid begeht.
Bei einer angenommenen Genauigkeit von 99,9 % des kombinierten HIV-Tests sowohl für positive als auch negative Ergebnisse (Sensitivität und Spezifität = 0,999) und der aktuellen Verbreitung von HIV (Stand 2009) in der deutschen Bevölkerung (82.000.000 Einwohner, davon 67.000 HIV-positiv) wäre ein allgemeiner HIV-Test verheerend.
HIV positiv HIV negativ HIV-Test positiv 66.933 82.000 148 933 HIV-Test negativ 67 ca. 82.000.000 Summe 82.000.000 Zwar würden von 67.000 tatsächlich Erkrankten lediglich 67 HIV-Infizierte fälschlicherweise nicht erkannt, aber ca. 82.000 Personen würden fälschlicherweise als HIV-positiv diagnostiziert. Von 148.933 positiven Ergebnissen wären etwa 55 % falsch positiv, also mehr als die Hälfte der Getesteten. Somit liegt die Wahrscheinlichkeit, dass jemand, der positiv getestet wurde, auch wirklich HIV-positiv ist, bei nur 45 %. Anders formuliert, der positive Vorhersagewert beträgt 45 %. Dieser, angesichts der sehr geringen Fehlerrate von 0,1 %, niedrige Wert liegt darin begründet, dass HIV nur bei etwa 0,08 % der Bundesbürger auftritt.
Herzinfarkt in den USA
In den USA werden pro Jahr etwa vier Millionen Frauen und Männer aufgrund von Schmerzen in der Brust unter der Verdachtsdiagnose Herzinfarkt in eine Klinik eingewiesen. Im Verlauf der aufwändigen und teuren Diagnostik stellt sich dann heraus, dass von diesen Patienten nur etwa 32 % tatsächlich einen Infarkt erlitten haben. Bei 68 % war die Diagnose Infarkt nicht korrekt (falsch positive Verdachtsdiagnose). Andererseits werden in jedem Jahr etwa 34.000 Patienten aus dem Krankenhaus entlassen, ohne dass ein tatsächlich vorhandener Herzinfarkt erkannt wurde (ca. 0,8 % falsch negative Diagnose).
Auch in diesem Beispiel ist die Sensitivität der Untersuchung ähnlich hoch, nämlich 99,8 %. Die Spezifität lässt sich nicht ermitteln, weil die falsch-positiven Ergebnisse der Untersuchung nicht bekannt sind. Bekannt sind nur die falsch-positiven Eingangsdiagnosen, die auf der Angabe "Herzschmerz" fußen. Betrachtet man ausschließlich diese Eingangsdiagnose, dann ist die Angabe der 34.000 Patienten, die fälschlich entlassen werden, wertlos, denn sie haben hiermit nichts zu tun. Man benötigt nämlich die Zahl der Falsch-Negativen, also jener Personen mit Herzinfarkt, die nicht eingewiesenen wurden, weil sie keinen Herzschmerz hatten.
Man sollte sich immer davor hüten, solche vermischte Angaben verwerten zu wollen und unbedingt auf eine präzise Formulierung der These achten.
Siehe auch
Literatur
Allgemein
- Hans-Peter Beck-Bornholdt, Hans-Hermann Dubben: Der Hund, der Eier legt. Erkennen von Fehlinformation durch Querdenken. ISBN 3-499-61154-6
- Gerd Gigerenzer: Das Einmaleins der Skepsis. Berlin: Berliner Taschenbuch Verlag, 2004 ISBN 3-8333-0041-8
Information Retrieval
- John Makhoul, Francis Kubala, Richard Schwartz und Ralph Weischedel: Performance measures for information extraction. In: Proceedings of DARPA Broadcast News Workshop, Herndon, VA, February 1999.
- R. Baeza-Yates und B. Ribeiro-Neto (1999). Modern Information Retrieval. New York: ACM Press, Addison-Wesley. Seiten 75 ff. ISBN 0-201-39829-X
- Christa Womser-Hacker: Theorie des Information Retrieval III: Evaluierung. In R. Kuhlen: Grundlagen der praktischen Information und Dokumentation. München. Saur, 5. Auflage 2004. Seiten 227-235. ISBN 3-598-11675-6, ISBN 3-598-11674-8
- C. V. van Rijsbergen: Information Retrieval. London; Boston. Butterworth, 2nd Edition 1979. ISBN 0-408-70929-4
- Jesse Davis und Mark Goadrich: The Relationship Between Precision-Recall and ROC Curves. In: 23rd International Conference on Machine Learning (ICML), 2006.
Weblinks
- Interaktive Veranschaulichung
- Leseprobe aus Gerd Gigerenzer: Das Einmaleins der Skepsis
- Information Retrieval – C. J. van Rijsbergen 1979
Einzelnachweise
- ↑ Thomas G. Dietterich: Approximate Statistical Tests for Comparing Supervised Classification Learning Algorithms. In: Neural Computation. 10, Nr. 7, 1. Oktober 1998, S. 1895-1923, doi:10.1162/089976698300017197.








Wikimedia Foundation.