- Konfidenzintervall
-
Das Konfidenzintervall (auch Vertrauensbereich, Vertrauensintervall oder Mutungsintervall genannt) ist ein Begriff aus der mathematischen Statistik. Er sagt etwas über die Präzision der Lageschätzung eines Parameters (zum Beispiel eines Mittelwertes) aus. Das Vertrauensintervall schließt einen Bereich um den geschätzten Wert des Parameters ein, der – vereinfacht gesprochen – mit einer zuvor festgelegten Wahrscheinlichkeit (dem Konfidenzniveau) die wahre Lage des Parameters trifft. Ein Vorteil des Konfidenzintervalls gegenüber der Punktschätzung eines Parameters ist, dass man an ihm direkt die Signifikanz ablesen kann. Ein für ein vorgegebenes Konfidenzniveau zu breites Vertrauensintervall weist auf einen zu geringen Stichprobenumfang hin. Entweder ist die Stichprobe tatsächlich „klein“, oder das untersuchte Phänomen ist so variabel, dass nur durch eine unrealistisch große Stichprobe ein Konfidenzintervall von akzeptabler Breite erreicht werden könnte.
Inhaltsverzeichnis
Definition
Es seien unabhängige und identisch verteilte Zufallsvariablen
 mit unbekanntem Verteilungsparameter θ gegeben. Wenn sich Stichprobenfunktionen U und V angeben lassen, so dass gilt:
mit unbekanntem Verteilungsparameter θ gegeben. Wenn sich Stichprobenfunktionen U und V angeben lassen, so dass gilt:dann heißt das (stochastische) Intervall [U,V] ein Konfidenzintervall für θ mit Konfidenzniveau γ (auch: ein γ-Konfidenzintervall). Die Realisationen u und v von U bzw. V bilden das Schätzintervall [u,v].
Da die Realisationen u und v der Grenzen U und V keine Zufallsvariablen sind und θ ein fixer Wert ist, kann man nicht sagen, dass das Schätzintervall [u,v] mit Wahrscheinlichkeit γ den unbekannten Parameter θ enthält. Es bedeutet vielmehr, dass im Mittel
 der Schätzintervalle den unbekannten Parameter überdecken. Dem nicht widersprechend, kann wie bereits von R. A. Fisher festgestellt, in manchen Modellen die Qualität des Schätzintervalls von den Daten abhängen und sogar zu Antworten führen, welche mit Blick auf die Daten unsinnig sind. Probleme mit solcher Post-Data-Inkohärenz führen zur Theorie der bedingten Inferenz.
der Schätzintervalle den unbekannten Parameter überdecken. Dem nicht widersprechend, kann wie bereits von R. A. Fisher festgestellt, in manchen Modellen die Qualität des Schätzintervalls von den Daten abhängen und sogar zu Antworten führen, welche mit Blick auf die Daten unsinnig sind. Probleme mit solcher Post-Data-Inkohärenz führen zur Theorie der bedingten Inferenz.Formale Definition
Es seien
 ,
,  :
:  ) ein statistisches Modell und Σ eine Menge.
) ein statistisches Modell und Σ eine Menge.  sei eine zu ermittelnde Kenngröße für den Parameter
sei eine zu ermittelnde Kenngröße für den Parameter  . Sei weiter
. Sei weiter  .
.Eine Abbildung
 heißt nun Konfidenzintervall zum Irrtumsniveau α von τ, wenn sie jedem möglichen Beobachtungsergebnis
heißt nun Konfidenzintervall zum Irrtumsniveau α von τ, wenn sie jedem möglichen Beobachtungsergebnis  eine Menge
eine Menge  zuordnet, so dass gilt:
zuordnet, so dass gilt:![\inf_{\vartheta \in \Theta} P_{\vartheta} [ x \in X : C(x) \ni \tau(\vartheta) ] \geq 1 - \alpha](c/ccc28a6ebd31c9db1f01d8cb9e197f49.png)
Beispiel einer Anwendung
Ein Physikdoktorand misst die ausstrahlende Wellenlänge bei einem Experiment unter zwei verschiedenen Bedingungen. Leider ist das Messgerät 10 Jahre alt und die Mechanik der Optik etwas wackelig. Obwohl also aufgrund des Versuchsansatzes nur das Licht einer Wellenlänge pro Bedingung erwartet wird, streut das Ergebnis bei unabhängigen Messungen. Der Physikdoktorand geht davon aus, dass das Messgerät mit gleicher Wahrscheinlichkeit zu große wie zu kleine Wellenlängen misst und dass extreme Messfehler unwahrscheinlicher sind als Messwerte nahe dem wahren Wert (Normalverteilung).
Daraufhin rechnet er aus den Ergebnissen der Einzelmessungen den arithmetischen Mittelwert aus. Für jede Bedingung einen Mittelwert. Er zeigt die Daten seinem Doktorvater, der wissen will, wie stark die Streuung der Messwerte war.
Jetzt rechnet der Doktorand den Standardfehler aus, um ein Maß für die Genauigkeit seiner beiden Mittelwerte zu bekommen und diese graphisch (als Fehlerbalken um den Mittelwert) darstellen zu können. Der Standardfehler bezieht neben der Streuung die Anzahl der Einzelmessungen mit ein. Je mehr Einzelmessungen vorgenommen werden desto näher kommt der errechnete Mittelwert dem wahren Wert und desto kleiner ist auch der Standardfehler.
Der Doktorvater ist aber immer noch nicht zufrieden, denn jetzt will er wissen, ob sich die zwei errechneten Mittelwerte unter den zwei unterschiedlichen Bedingungen statistisch signifikant voneinander unterscheiden oder ob es nur aufgrund der Ungenauigkeit des Gerätes zu unterschiedlichen Mittelwerten kommt. Daraufhin rechnet der Doktorand die Vertrauensintervalle um die Mittelwerte aus, die in Abhängigkeit von der Streuung und der Anzahl der Einzelmessungen den Bereich angeben, der jeweils den wahren Wert mit hoher Wahrscheinlichkeit mit einschließt. Wählt man ein 95 %-Konfidenzintervall (das heißt: in 95 von 100 Fällen enthalten die errechneten Intervallgrenzen den wahren Wert) und die Balken des Konfidenzintervalls der beiden Mittelwerte überschneiden sich nicht, dann werden die Mittelwerte in der Regel als signifikant unterschiedlich bezeichnet (wird häufig mit einem * markiert). Hierbei handelt es sich aber nur um eine Faustregel: Es gibt sehr wohl Fälle, in denen sich die Unter- und Obergrenze zweier Konfidenzintervalle nicht überschneiden, die Mittelwerte aber dennoch nicht signifikant unterschiedlich sind. Bei einem 99 %-Konfidenzintervall und fehlender Überlappung gelten sie als hochsignifikant unterschiedlich (Markierung: **).
Beschreibung des Verfahrens
Man interessiert sich für den unbekannten Parameter θ einer Grundgesamtheit. Diese wird durch eine Schätzfunktion aus einer Stichprobe vom Umfang n geschätzt. Es wird davon ausgegangen, dass die Stichprobe eine einfache Zufallsstichprobe ist, in etwa die Grundgesamtheit widerspiegelt und dass deshalb die Schätzung in der Nähe des wahren Parameters liegen müsste. Die Schätzfunktion ist eine Zufallsvariable mit einer Verteilung, die den Parameter θ enthält.
Man kann zunächst mit Hilfe der Verteilung ein Intervall angeben, das den unbekannten wahren Parameter γ mit einer Wahrscheinlichkeit 1−α überdeckt. 1−α wird Konfidenzniveau oder Konfidenzkoeffizient genannt. Ermitteln wir z. B. das 95 %-Konfidenzintervall für den wahren Erwartungswert μ einer Population, dann bedeutet dies, dass wir ein Konfidenzintervall ermitteln, das bei durchschnittlich 95 von 100 gleichgroßen Zufallsstichproben den Erwartungswert enthält.
Das Verfahren wird anhand eines normalverteilten Merkmals mit dem unbekannten Erwartungswert μ und der bekannten Varianz σ2 demonstriert: Es soll der Erwartungswert μ dieser Normalverteilung geschätzt werden. Verwendet wird die erwartungstreue Schätzfunktion: der Stichprobenmittelwert
 .
.Der Erwartungswert der Population wird anhand unserer Stichprobe geschätzt
- Schätzfunktion:

- Punktschätzung:

wobei die Zufallsvariable Xi (i=1,…,n) für die i-te Beobachtung (vor der Ziehung der Stichprobe) steht. Es ist
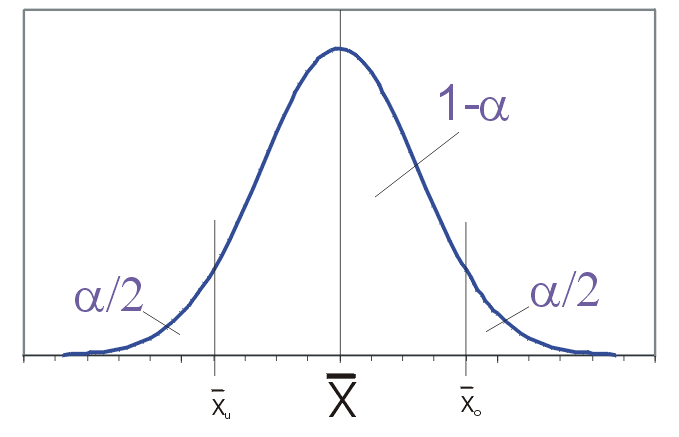
Die Grenzen des zentralen Schwankungsintervalls
![[\bar x_u; \bar x_o]](7/da71af2be00d7ff08cf7abac2b9c4e03.png) ,
,
in dem
 mit der Wahrscheinlichkeit 1−α liegt, bestimmen sich aus der Beziehung
mit der Wahrscheinlichkeit 1−α liegt, bestimmen sich aus der Beziehung .
.
Man standardisiert zur Standardnormalverteilung
 und erhält für die standardisierte Zufallsvariable
und erhält für die standardisierte Zufallsvariabledie Wahrscheinlichkeit
 ,
,
wobei
 das (1-α/2)-Quantil der Standardnormalverteilung ist. Löst man nach μ auf, so ergibt sich aus
das (1-α/2)-Quantil der Standardnormalverteilung ist. Löst man nach μ auf, so ergibt sich ausdas (1−α)-Konfidenzintervall für μ
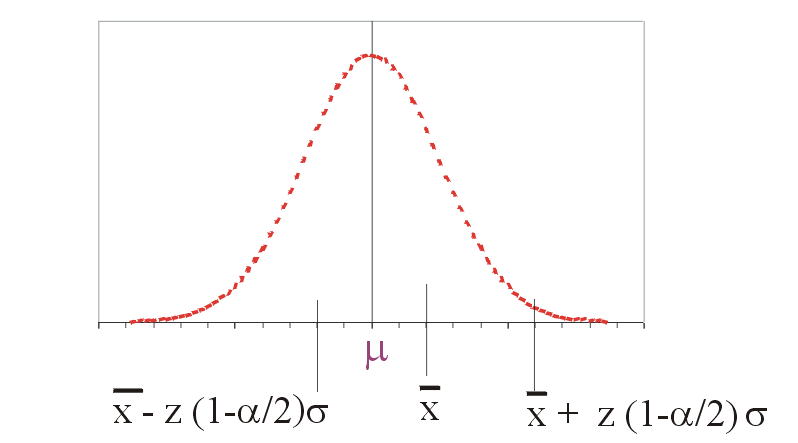
 Mögliche Lage des unbekannten µ im Schätzintervall um das beobachtete
Mögliche Lage des unbekannten µ im Schätzintervall um das beobachtete
 .
.Das Schätzintervall, die Realisation eines Konfidenzintervalles anhand einer konkreten Stichprobe, ergibt sich dann als
Die Grenzen des Schätzintervalles hängen jedoch von
ab und ändern sich damit von Stichprobe zu Stichprobe. Ist die Stichprobe aber extrem ausgefallen, überdeckt das Intervall den Parameter nicht. Dies ist in 100α% aller Stichproben der Fall, d.h das durch bestimmte Intervall überdeckt den wahren Parameter μ also mit einer Wahrscheinlichkeit von 1−α.Von besonderem Interesse ist die Breite des Konfidenzintervalls. Diese bestimmt sich durch die Standardabweichung der Schätzfunktion und das gewählte Konfidenzniveau. Durch Erhöhung des Stichprobenumfangs kann die Breite verringert werden. Erwünscht ist in der Regel ein möglichst schmales Konfidenzintervall, denn dies weist bei konstantem Konfidenzniveau auf eine genaue Schätzung hin.
Ausgewählte Schätzintervalle
Übersicht für stetige Verteilungen
Erwartungswert eines normalverteilten Merkmals mit bekannter Varianz σ:
 ist das (1−α/2)-Quantil der Standardnormalverteilung.
ist das (1−α/2)-Quantil der Standardnormalverteilung.![\left[ { \bar x-z_{(1-\tfrac{\alpha}{2})}\frac {\sigma}{\sqrt{n}} \ ; \ \bar x+z_{(1-\tfrac{\alpha}{2})}\frac{\sigma}{\sqrt{n}}} \right]](a/c9a89de4f70292e1ebd7ca181205caf8.png)
Erwartungswert eines normalverteilten Merkmals mit unbekannter Varianz:
Die Varianz der Grundgesamtheit wird durch die korrigierte Stichprobenvarianzgeschätzt.
 ist das (1−α/2)-Quantil der t-Verteilung mit n-1 Freiheitsgraden.
ist das (1−α/2)-Quantil der t-Verteilung mit n-1 Freiheitsgraden.Für n > 30 kann das Quantil der t-Verteilung näherungsweise durch das entsprechende Quantil der Standardnormalverteilung ersetzt werden.
![\left[{\bar x-t_{(1-\tfrac{\alpha}{2};n-1)}\frac{s}{\sqrt{n}}\ ;\ \bar x+t_{(1-\tfrac{\alpha}{2}; n-1)} \frac{s}{\sqrt{n}}} \right]](b/28bf914f5e586bd0bbbf73134ce0221f.png)
Erwartungswert eines unbekannt verteilten Merkmals mit unbekannter Varianz:
Falls n genügend groß ist, kann aufgrund des zentralen Grenzwertsatzes das Konfidenzintervall bestimmt werden.![\left[ { \bar x-z_{(1-\tfrac {\alpha}{2})}\frac{s}{\sqrt{n}}\ ;\ \bar x+z_{(1-\tfrac{\alpha}{2})}\frac{s}{\sqrt{n}}} \right]](3/fd3548d72d3d6d10d88a65375f381c07.png)
Standardabweichung eines normalverteilten Merkmals:  ist das p-Quantil der χ2-Verteilung mit k Freiheitsgraden.
ist das p-Quantil der χ2-Verteilung mit k Freiheitsgraden.![\left[ \ s\sqrt{\frac {n-1}{ \chi^2_{(1-\tfrac {\alpha}{2}; n-1)}}} ; s\sqrt{\frac {n-1}{\chi^2_{(\tfrac {\alpha}{2}; n-1)}}}\ \right]](a/0ea07744c31a0fcd99a77145ea5cbb1f.png)
Diskrete Verteilungen
Konfidenzintervalle für den Parameters p der Binomialverteilung sind beschrieben in dem
Das sogenannte Clopper-Pearson-Konfidenzintervall kann mit Hilfe der Beta- oder F-Verteilung bestimmt werden. Dieses Konfidenzintervall wird auch exakt genannt, da das geforderte Konfidenzniveau tatsächlich eingehalten wird. Bei Näherungsmethoden, die (meistens) auf der Approximation der Binomialverteilung durch die Normalverteilung basieren, wird das Konfidenzniveau oft nicht eingehalten.
Ist die Zahl der Elemente in der Grundgesamtheit bekannt, kann für den Parameter (mit Hilfe eines Korrekturfaktors) auch ein Konfidenzintervall für ein Urnenmodell ohne Zurücklegen angegeben werden.[1]
Konfidenzintervalle und Hypothesentests
Konfidenzintervalle kommen auch bei Hypothesentests zum Einsatz: Testet man von einem Parameter θ die Nullhypothese: θ = θ0, dann ist das Kriterium für das Ablehnen der Nullhypothese bei Signifikanzniveau α, ob das entsprechende (1-α)-Konfidenzintervall den Wert θ0 enthält oder nicht. Daher ersetzen Konfidenzintervalle gelegentlich auch Hypothesentests.
Beispielsweise testet man in der Regressionsanalyse, ob im multiplen Regressionsmodell mit der geschätzten Regressionshyperebene
die wahren Regressionskoeffizienten βj (j = 1, … , m) gleich Null sind. Wenn die Hypothese nicht abgelehnt wird, sind die entsprechenden Regressoren xj vermutlich für die Erklärung der abhängigen Variablen y unerheblich. Eine entsprechende Information liefert das Konfidenzintervall für einen Regressionskoeffizienten: Überstreicht das Konfidenzintervall die Null, kann mit einer Wahrscheinlichkeit von 1-α der Regressionskoeffizient ebenso gut Null sein, d. h. er ist statistisch insignifikant.
Beispiele für ein Konfidenzintervall
Beispiel 1 Ein Unternehmen möchte flächendeckend auf dem Markt ein neues Spülmittel einführen. Um die Käuferakzeptanz auszuloten, wird in einem Supermarkt dieses Produkt mit hohem Werbeaufwand platziert. Es soll mit dieser Aktion der durchschnittliche tägliche Absatz in einem Supermarkt dieser Größe geschätzt werden. Man definiert nun den täglichen Absatz als Zufallsvariable X [Stück] mit den unbekannten Parametern Erwartungswert μ und der Varianz σ2. Man geht auf Grund langjähriger Beobachtungen hier davon aus, dass X annähernd normalverteilt ist. Die Marktforschungsabteilung hat einen Konfidenzkoeffizienten von 0,95 als ausreichend erachtet. Es wird nun 16 Tage lang der tägliche Absatz erfasst. Es hat sich beispielsweise ergeben
Absatz x 110 112 106 90 96 118 108 114 107 90 85 84 113 105 90 104 Bei normalverteilter Grundgesamtheit mit unbekannter Varianz wird das Konfidenzintervall für den Erwartungswert angegeben als
Es ist
und
Es ist das (1-α/2)-Quantil der t-Verteilung mit 15 Freiheitsgraden
Das 95 %-Konfidenzintervall berechnet sich dann als
In 95 % aller Fälle beinhaltet also das Intervall des durchschnittlichen täglichen Absatzes an Spülmittelflaschen zwischen ca. 96 und 108 Stück den wahren Mittelwert. Dieses Intervall ist relativ schmal, so dass man gut mit dieser Information planen kann.
Beispiel 2 Ein Unternehmen lieferte ein Los von 6000 Stück (z.B. Schrauben) an den Kunden. Dieser führt mittels Stichprobennahme gemäß der internationalen Norm ISO 2859-1[2] eine Eingangsprüfung durch. Dabei werden z.B. 200 Schrauben (je nach gewähltem AQL) zufällig über das gesamte Los gezogen und auf Übereinstimmung mit den vereinbarten Anforderungen (Qualitätsmerkmalen) geprüft. Von den 200 geprüften Schrauben erfüllen 10 Stück die gestellten Anforderungen nicht. Mittels der Berechnung des Konfidenzintervalls (Excel-Funktion BETAINV) kann der Kunde abschätzen, wie groß der zu erwartende Anteil fehlerhafter Schrauben im ganzen Los ist: bei einem Konfidenzniveau von 95% berechnet man das Clopper-Pearson-Konfidenzintervall [2,4%,9%] für den Anteil fehlerhafter Schrauben im Los (Parameter: n=200, k=10).Literatur
- U. Krengel: Einführung in die Wahrscheinlichkeitstheorie und Statistik. 8. Auflage. Vieweg, 2005.
- J. Hartung: Statistik. 14. Auflage. Oldenbourg, 2005.
Weblinks
- Java-Applet zur Visualisierung des Vertrauensbereichs
- Konfidenzintervalle und Hypothesentests
- Konfidenzintervalle so einfach wie möglich erklärt
Einzelnachweise
- ↑ Siehe zum Beispiel die Abschnitte 3.1.1 und 3.2 bei Hartung. Hier werden die Wilson- und Clopper-Pearson-Intervalle, sowie der Korrekturfaktor für die hypergeometrische Verteilung besprochen.
- ↑ Annahmestichprobenprüfung anhand der Anzahl fehlerhaften Einheiten oder Fehler [Attributprüfung] - Teil 1: Nach der annehmbaren Qualitätsgrenzlage [AQL] geordnete Stichprobenpläne für die Prüfung einer Serie von Losen
Kategorie:- Schätztheorie





![\left[ { \bar X-z_\left( 1-\tfrac {\alpha}{2} \right) \frac {\sigma}{\sqrt{n}} ; \ \bar X+z_\left( 1-\tfrac {\alpha}{2} \right) \frac {\sigma}{\sqrt{n}}} \right].](9/bb9074c84d3b53957650eb15363e9682.png)
![\left[ { \bar x-z_\left( 1-\tfrac {\alpha}{2} \right) \frac {\sigma}{\sqrt{n}} ; \ \bar x+z_\left( 1-\tfrac {\alpha}{2} \right) \frac {\sigma}{\sqrt{n}}} \right].](5/d9580f7064395479a8f446b3c23ac896.png)


![\left[ { \bar x-t_\left( 1-\frac {\alpha}{2}; n-1 \right) \frac {s}{\sqrt{n}} \ ; \ \bar x+t_ \left( 1-\frac {\alpha}{2} ; n-1 \right) \frac {s}{\sqrt{n}}} \right]](4/0740897cb025ebe86cc1afc425420b91.png)



![\left[ { 102 - 2{,}13 \frac {\sqrt{123{,}73}} {\sqrt{16}} ; 102 + 2{,}13 \frac {\sqrt{123{,}73}} {\sqrt{16}} } \right] = [102 -5{,}92; 102 + 5{,}92] = [96{,}08; 107{,}92]](a/4cae51a59bca330cd062ce93b1fcc411.png)
Wikimedia Foundation.