- Häufigkeitsgebirge
-
Das deutsche Alphabet ist diejenige Variante des lateinischen Alphabets, die zur Schreibung der deutschen Sprache verwendet wird. Im heutigen standardisierten Gebrauch umfasst es die 26 Grundbuchstaben des lateinischen Alphabets zuzüglich der drei Umlaute (Ä, Ö, Ü). Bei den Kleinbuchstaben kommt in Deutschland und Österreich, nicht aber in der Schweiz und in Liechtenstein, das Eszett (ß) (auch „scharfes S“ genannt) hinzu. Die einzelnen Buchstaben haben sächliches Genus. Das heißt, man sagt „das A“, „das B“ usw.
Die Buchstaben des Deutschen Alphabets sind:
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z Ä Ö Ü
a b c d e f g h i j k l m n o p q r s t u v w x y z ä ö ü ß
Sowohl in der Schreibung von Mundarten wie in historischen Dokumenten werden und wurden darüber hinaus zahlreiche zusätzliche Buchstaben gebraucht. Das Gleiche gilt für die Schreibung von Fremdwörtern.
Die deutsche Sprache ist sehr vielseitig. Aus diesem Grund ist es wichtig, ein breites Spektrum von Texten zu analysieren, wenn man allgemein gültige Aussagen zum deutschen Alphabet tätigen möchte. Möchte man die Häufigkeit der Buchstaben des Alphabets in der deutschen Sprache untersuchen, ist es weiterhin notwendig, relativ lange Texte zu untersuchen, die nicht übermäßig mit Fremdwörtern oder Anglizismen durchsetzt sind, da dies die Analyse verfälschen würde.
Herkunft der Umlautbuchstaben und des Eszetts
 Entstehung der Umlautpunkte am Beispiel des ä
Entstehung der Umlautpunkte am Beispiel des äDie Umlautbuchstaben (ä, ö und ü) entstanden aus der Kombination des jeweiligen lateinischen Buchstaben (also a, o und u) mit einem den Umlaut anzeigenden e. Diese Markierung wurde zunächst (bis zum 15. Jahrhundert) nur fakultativ verwendet – der Buchstabe u konnte sowohl u wie ü bedeuten. Ein e oder i konnte jedoch zur Unterscheidung seit etwa dem 13. Jahrhundert über den Buchstaben gesetzt werden, seltener auch hinter den umgelauteten Buchstaben. Dieses kleine „e“ sieht in handschriftlicher Schrift spätestens im 15. Jahrhundert wie zwei senkrechte Striche aus, aus denen schließlich die zwei heute häufig verwendeten Punkte wurden. Einige Schriftarten verwenden auch immer noch die senkrechten Striche für die Umlautbuchstaben. Die Umlautbuchstaben werden heute auch in zahlreichen anderen Sprachen verwendet.
Das ß, das auch als scharfes s bekannt ist, ist ursprünglich eine Ligatur aus dem langen ſ (s) und entweder dem runden s oder dem z in den spätmittelalterlichen Bastarden und der neuzeitlichen Frakturschrift. Ab etwa dem Anfang des 19. Jahrhunderts wurde die Antiqua auch in deutschsprachigen Ländern gebräuchlicher. Damals enthielten die meisten Antiqua-Schriften keine Buchstaben für das ß, Drucke aus dem 19. Jahrhundert sind daher oftmals ohne ß gesetzt. Bei der Orthographischen Konferenz von 1901 wurde festgelegt, dass die Schriftgießereien in Zukunft ihre Antiqua-Schriften mit der Letter ß zu liefern hätten und für vorhandene Schriften ein ß nachzuliefern sei.
In Versalschrift wird ersatzweise SS oder (seltener) SZ geschrieben. Für amtliche Dokumente und Formulare ist in versal geschriebenen Namen jedoch zur Unterscheidung ein ß zu schreiben. Anfang des 20. Jahrhunderts wurde die Schaffung eines Großbuchstaben Versal-ß diskutiert, von den bestehenden Entwürfen hat sich aber keiner durchgesetzt. Am 4. April 2008 wurde jedoch das große ß in den Unicode-Standard Version 5.1 als „U+1E9E“ aufgenommen.[1]Das lange ſ wurde auch in der Antiqua gelegentlich gesetzt, es findet sich beispielsweise noch im Leipziger Duden von 1951.
In der deutschen Schreibschrift sind ſ und h einander sehr ähnlich (h hat in der Unterlänge eine Schleife, ſ nicht), speziell bei schwungvoller Schreibweise sind diese Buchstaben leicht zu verwechseln. Hieraus erklärt sich ein typischer Fehler, der bei der Übertragung von Eigennamen von deutscher Schrift in lateinische Schrift vorgekommen ist: So manche Familie Weiſs heißt heute Weihs.
Die Bezeichnung scharfes s bedeutet eigentlich stimmloses s. Nach der Abschaffung der Schlussbuchstabigkeit des ß steht der Buchstabe heute (außer in Namen) nach Langvokal und Diphthong und bezeichnet dort ein stimmloses s.
Häufigkeit der Buchstaben im Deutschen
Wie wohl in allen Sprachen kommen auch im Deutschen die einzelnen Buchstaben verschieden häufig vor. In verschiedenen Untersuchungen wurde die prozentuale Verteilung untersucht. Die Ergebnisse sind vor allem aus Sicht der Linguistik, Datenverschlüsselung und Datenkomprimierung interessant.
Trotz kleinerer Abweichungen kommen alle Untersuchungen zu folgenden Ergebnissen:
- Der häufigste Buchstabe ist das E, gefolgt vom N.
- Der seltenste Buchstabe ist das Q.
Für genaue Ergebnisse für die einzelnen Buchstaben siehe den Artikel Buchstabenhäufigkeit.
Die 30 im Deutschen Alphabet verwendeten Buchstaben lassen sich in drei Klassen unterteilen:
- Sehr häufige Buchstaben (Häufigkeit: 4 % und darüber) A, D, E, H, I, N, R, S, T, U − Diese Buchstaben sind auch Bestandteil einiger häufiger grammatischer Endungen, vor allem der Verbformen. Fast alle Vokale (außer dem O) gehören ins obere Drittel.
- Häufige Buchstaben (Häufigkeit: 1–4 %): B, C, F, G, K, L, M, O, W, Z − Diese Buchstaben kommen nicht ganz so häufig vor wie die ersten zehn, sind aber auch in jedem kürzeren Text anzutreffen. Das C tritt übrigens immer in den Verbindungen ch, ck oder sch auf, nur in Eigennamen und Fremdwörtern auch alleine.
- Weniger häufige und seltene Buchstaben (Häufigkeit: unter 1 %): J, P, Q, V, X, Y, Ä, Ö, Ü, ß − Hierbei können Q, X und Y als „Exoten“ gelten. Q kommt immer in der Verbindung qu vor. X und Y werden nur in Eigennamen und Fremdwörtern verwendet (Ausnahmen sind zehn Wörter mit X: Axt, Buxe, Faxen, feixen, Haxe, Hexe, kraxeln, Nixe, Text, verflixt). Das ß existiert seit einiger Zeit sowohl als Klein- als auch als Großbuchstabe, in Kapitälchen-Schrift.
Buchstabenverteilung in deutschsprachigen Texten
 Monogramm-Häufigkeitsgebirge: Die Buchstaben-Häufigkeitsverteilung eines längeren deutschen Textes.
Monogramm-Häufigkeitsgebirge: Die Buchstaben-Häufigkeitsverteilung eines längeren deutschen Textes.Der häufigste Buchstabe in der deutschen Sprache ist das „E“, gefolgt vom Leerzeichen. Die Verteilung der Satzzeichen erlaubt Rückschlüsse auf die mittlere Wortlänge (siehe unten). Die Art der Texte (Lyrik, Prosa, Bedienungsanleitungen etc.) hat keinen Einfluss auf die Buchstabenverteilung.
Für die Entzifferung von chiffrierten Texten ist es wichtig, Aussagen über Bigramme (auch Digramme, das sind Buchstaben-Paare) und Trigramme (Dreiergruppen von Buchstaben) zu treffen. Sie geben Hinweise auf den Klartext; so brach Friedrich Wilhelm Kasiski über die Verteilung von Bigrammen die Vigenère-Verschlüsselung. Nicht nur die Häufigkeit von Buchstaben, auch die Verteilung von Buchstabengruppen ist typisch für die zugrunde liegende Sprache.
 Bigramm-Häufigkeitsgebirge: Verteilung der Bigramme in einem deutschen Text.
Bigramm-Häufigkeitsgebirge: Verteilung der Bigramme in einem deutschen Text.Im Deutschen sind die Digramme ER und EN am häufigsten vertreten und zwar am Wortende, wie die Trigramm-Analyse zeigt. Ohne Leerzeichen sind es die Trigramme SCH und DER, die die Verteilungsliste anführen.
 Trigramm-Häufigkeitsgebirge: Verteilung der Trigramme in einem deutschen Text. Die Tripel ER_ und EN_ sind am häufigsten („_“ steht für das Leerzeichen).
Trigramm-Häufigkeitsgebirge: Verteilung der Trigramme in einem deutschen Text. Die Tripel ER_ und EN_ sind am häufigsten („_“ steht für das Leerzeichen).Die mittlere Wortlänge kann als der Quotient aus der Gesamtzahl der Buchstaben und der Anzahl der Leerzeichen in einem Text bestimmt werden. Die mittlere Satzlänge kann aus der Gesamtzahl der Buchstaben geteilt durch die Anzahl der Satzzeichen und durch die mittlere Wortlänge berechnet werden. Beispiel: Ein Text hat 166.636 Buchstaben und 26.056 Leerzeichen. Damit ist die mittlere Wortlänge bei dieser Analyse 6,4 Buchstaben je Wort (= 166.636 Buchstaben : 26.056 Leerzeichen). Die mittlere Satzlänge beträgt 5 Wörter pro Satz (= 26.056 Leerzeichen : 5225 Satzzeichen).
Auch in der Linguistik, insbesondere der Quantitativen Linguistik, ist die Buchstabenverteilung ein Untersuchungsgegenstand. Hier geht es unter anderem um die Rangordnung der Buchstaben in Texten oder auch im Wörterbuch und die Frage, ob man die mathematisch modellieren kann (siehe Buchstabenhäufigkeit). In der Graphematik wird die typische Verteilung und Kombinierbarkeit von Buchstaben (genauer: Graphemen) einer Sprache innerhalb von Wörtern (und Silben) im Rahmen der Graphotaktik untersucht. Beispielsweise kann der Anfangsrand von üblichen deutschen Wörtern aus höchstens vier Randgraphemen (vier Konsonantengraphemen: Konsonantencluster) bestehen: z. B. schw in schwitzen. Weiteres Beispiel: Die Kerngraphemfolge (Vokalgraphemfolge) ie tritt am Anfang eines Wortes nicht auf.
Analog dazu wird in der Phonologie im Rahmen der Phonotaktik die typische Verteilung und Kombinierbarkeit von Phonemen (Lauten) einer Sprache untersucht. Aus solchen Beobachtungen und dem Vergleich beider Ebenen lassen sich z. B. orthographische Regularitäten ableiten: Das Phonem /i:/ (langes „i“) kommt wortinitial vor, ie, das normalerweise zur Darstellung von /i:/ verwendet wird, kommt wortinitial nicht vor (stattdessen einfaches i oder, vor l, m, n, r, ih), vgl. Igel, aber Ziegel, ihm, aber Riemen. Daraus lässt sich schlussfolgern, dass es eine orthographische Beschränkung gibt, die ie zur Darstellung von /i:/ am Wortanfang ausschließt.
Vergleich mit der englischen Sprache
Die Buchstabenverteilung einer Sprache, also ihr Häufigkeitsgebirge, wird auch als Fingerabdruck einer Sprache (engl.: „fingerprint“) bezeichnet. Ein Fingerabdruck ist etwas Einmaliges und Eindeutiges. Beim Vergleich der deutschen Sprache mit anderen Sprachen wird dies recht deutlich.
Im Englischen ist das E der meistgenutzte Buchstabe. Das häufigste Zeichen jedoch ist das Leerzeichen. Englische Wörter werden nicht zusammengesetzt, wie das Beispiel eines Satzgefüges zeigt: The_tire_of_the_car (4 Leerzeichen, 3 E) und Der_Autoreifen (1 Leerzeichen, 3 E).
Alphabetische Sortierung
- Siehe auch den Hauptartikel Alphabetische Sortierung
Prinzipiell erfolgt die Sortierung entsprechend der Reihenfolge der Buchstaben im Alphabet. Dabei gibt es aber einige signifikante Abweichungen und Besonderheiten. Diese betreffen die Einordnung von Wörtern mit Umlauten und „ß“ sowie Ziffern und Sonderzeichen.
In Wörterbüchern und ähnlichen Auflistungen werden die Umlaute Ä, Ö, Ü wie A, O und U behandelt, ß wie ss (Alter, älter, Altes). Bei der im Telefonbuch üblichen Sortierung werden die Umlaute hingegen wie Ae, Oe und Ue eingeordnet. Beide Varianten sind in der DIN-Norm 5007:1991 beschrieben.
Im gedruckten österreichischen Telefonbuch (seit etwa 1990 vom Verlag herold.at) finden sich unterschiedliche Reihungen: Im Ortsverzeichnis kommen nach z erst die Umlaute und ß, also: Tyrnau, Tösens und Weiz, Weißbach sowie Zwettl, Zürs, Öblarn (gut versteckt unter dem Titel „Z“). Die Infoseiten reihen jedoch Ämter vor Arbeit, die Gelben Seiten ihre Rubrik Ärzte vor Audio. Im Namensverzeichnis Bayr, dann erst Bäck, und AZ, A1, (nach Spaltenüberschrift „Ä“) Ärzte. Darin Orte: Ursprung, Übersbach. Mit Abfolge wie a (mit aa, ... az), ä, b.
Ligaturen und andere Zeichen im Schriftsatz
Zusätzlich zu den normalen Buchstaben werden Sonderzeichen wie zum Beispiel die Ligatur @ verwendet.
Namen der Buchstaben
Für die Schreibung der meisten deutschen Buchstabennamen gibt es keine Tradition. Nur für einige sind Schreibungen in den einschlägigen Wörterbüchern zu finden, zum Teil auch nur als Bestandteil von zusammengesetzten und abgeleiteten Wörtern (Tezett, ausixen). Die existierenden Schreibungen sind im Vergleich nicht konsequent (Zett, Eff, aber Jot, Es). Die Namensgebung selbst (siehe Aussprache) ist im deutschen Sprachgebiet weitgehend einheitlich.
Im Folgenden ist zunächst die Aussprache (IPA) genannt, dann folgen die nach den Rechtschreibregeln möglichen Schreibungen (da aa und oo im Auslaut ziemlich unüblich sind, sind Varianten damit nicht genannt; ebenso wenig denkbare Varianten mit ä, z. B. Änn, Än). Fett sind die Schreibungen gesetzt, die auch in Wörterbüchern zu finden sind.
- A/a: [aː] Ah, A (nur in Abece)
- Ä/ä: [ɛː] Äh, Ä; gelegentlich auch A-Umlaut
- B/b: [beː] Beh, Bee, Be (nur in Abece)
- C/c: [tseː] Ceh, Cee, Ce (nur in Abece)
- D/d: [deː] Deh, Dee, De
- E/e: [eː] Eh, Ee, E
- F/f: [ɛf] Eff (nur in Effeff), Ef
- G/g: [geː] Geh, Gee, Ge
- H/h: [haː] Hah, Ha
- I/i: [iː] Ih, I
- J/j: [jɔt] Jott, Jot; in Österreich auch [jeː] Jeh, Jee, Je
- K/k: [kaː] Kah, Ka
- L/l: [ɛl] Ell, El
- M/m: [ɛm] Emm, Em
- N/n: [ɛn] Enn, En
- O/o: [oː] Oh, O
- Ö/ö: [øː] Öh, Ö; gelegentlich auch O-Umlaut
- P/p: [peː] Peh, Pee, Pe
- Q/q: [kuː] Quh, Qu; in Österreich auch [kveː] Queh, Quee, Que
- R/r: [ɛr] Err, Er
- S/s: [ɛs] Ess, Es (nur in Eszett)
- ß: [ɛs'tsɛt] Esszett, Eszett, Esszet, Eszet; auch Scharfes [ɛs] (weitere Namen siehe unter ß)
- T/t: [teː] Teh, Tee, Te (nur in Tezett)
- U/u: [uː] Uh, U
- Ü/ü: [yː] Üh, Ü; gelegentlich auch U-Umlaut
- V/v: [faʊ] Vau
- W/w: [veː] Weh, Wee, We
- X/x: [iks] Ix (nur in ausixen)
- Y/y: ['ʏpsilɔn] Ypsilon
- Z/z: [tsɛt] Zett, Zet
Reihenfolge
Jeder Buchstabe hat eine bestimmte Position im Alphabet. Die Reihung ist folgendermaßen:
Einzelnachweise
Literatur
- Regeln und Wörterverzeichnis. Überarbeitete Fassung des amtlichen Regelwerks 2004. Rat für deutsche Rechtschreibung, München und Mannheim, Februar 2006.
Siehe auch
- Alphabet
- Kategorie:Schriftzeichen
- Zipfsches Gesetz
- Buchstabiertafel
Weblinks
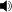 Deutsches Alphabet?/i
Deutsches Alphabet?/i- Programm zum Einüben des deutschen Alphabets



Wikimedia Foundation.