- Gausssche Verteilung
-
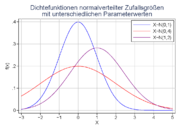 Dichten normalverteilter Zufallsgrößen
Dichten normalverteilter ZufallsgrößenDie Normal- oder Gauß-Verteilung (nach Carl Friedrich Gauß) ist ein wichtiger Typ kontinuierlicher Wahrscheinlichkeitsverteilungen. Ihre Wahrscheinlichkeitsdichte wird auch Gauß-Funktion, Gauß-Kurve, Gauß-Glocke oder Glockenkurve genannt.
Die besondere Bedeutung der Normalverteilung beruht unter anderem auf dem zentralen Grenzwertsatz, der besagt, dass eine Summe von n unabhängigen, identisch verteilten Zufallsvariablen im Grenzwert
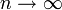 normalverteilt ist. Das bedeutet, dass man Zufallsvariablen dann als normalverteilt ansehen kann, wenn sie durch Überlagerung einer großen Zahl von unabhängigen Einflüssen entstehen, wobei jede einzelne Einflussgröße einen im Verhältnis zur Gesamtsumme unbedeutenden Beitrag liefert.
normalverteilt ist. Das bedeutet, dass man Zufallsvariablen dann als normalverteilt ansehen kann, wenn sie durch Überlagerung einer großen Zahl von unabhängigen Einflüssen entstehen, wobei jede einzelne Einflussgröße einen im Verhältnis zur Gesamtsumme unbedeutenden Beitrag liefert.Viele natur-, wirtschafts- und ingenieurswissenschaftliche Vorgänge lassen sich durch die Normalverteilung entweder exakt oder wenigstens in sehr guter Näherung beschreiben (vor allem Prozesse, die in mehreren Faktoren unabhängig voneinander in verschiedene Richtungen wirken).
Zufallsgrößen mit Normalverteilung benutzt man zur Beschreibung zufälliger Vorgänge wie:
- zufällige Messfehler,
- zufällige Abweichungen vom Nennmaß bei der Fertigung von Werkstücken,
- Beschreibung der brownschen Molekularbewegung.
In der Versicherungsmathematik ist die Normalverteilung geeignet zur Modellierung von Schadensdaten im Bereich mittlerer Schadenshöhen.
In der Messtechnik wird häufig eine Normalverteilung angesetzt, die die Streuung der Messfehler beschreibt. Hierbei ist von Bedeutung, wie viele Messpunkte innerhalb einer gewissen Streubreite liegen. Die Standardabweichung σ beschreibt die Breite der Normalverteilung. Berücksichtigt man die tabellierten Werte der Verteilungsfunktion, gilt näherungsweise folgende Aussage:
- 68,27 % aller Messwerte haben eine Abweichung von höchstens σ vom Mittelwert,
- 95,45 % aller Messwerte haben eine Abweichung von höchstens 2σ vom Mittelwert,
- 99,73 % aller Messwerte haben eine Abweichung von höchstens 3σ vom Mittelwert.
Somit kann neben dem Mittelwert auch der Standardabweichung eine physikalische Bedeutung zugeordnet werden.
Definition
Eine stetige Zufallsvariable X mit der Wahrscheinlichkeitsdichte
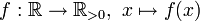
heißt μ-σ-normalverteilt, auch geschrieben als
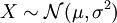 oder (μ,σ2)-normalverteilt, wobei μ der Erwartungswert und σ die Standardabweichung sind.
oder (μ,σ2)-normalverteilt, wobei μ der Erwartungswert und σ die Standardabweichung sind.Die Verteilungsfunktion der Normalverteilung ist gegeben durch
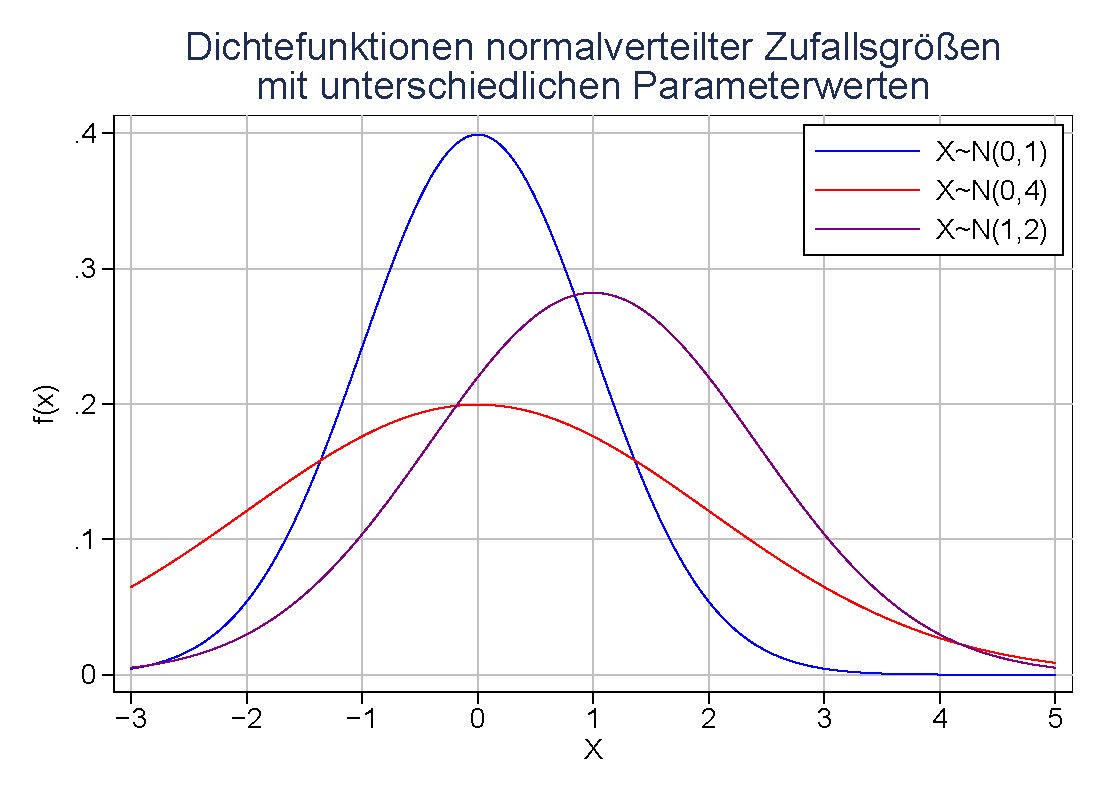
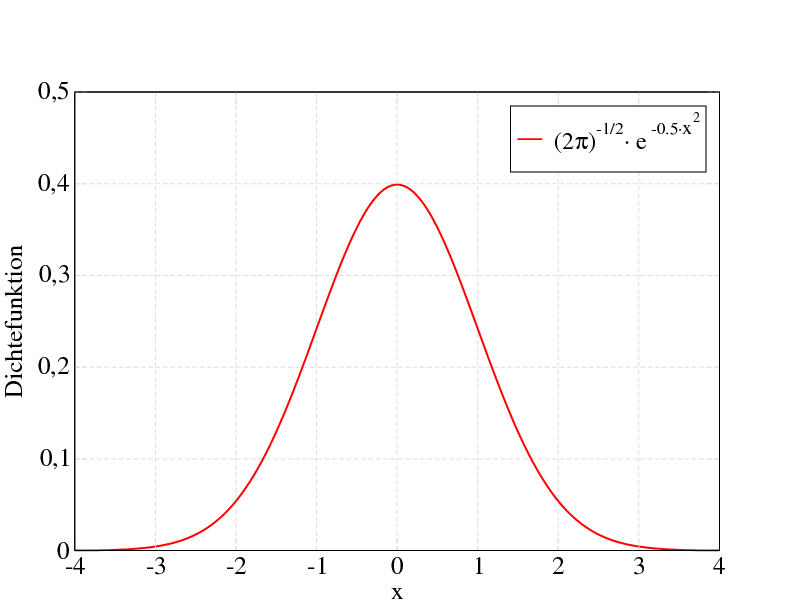
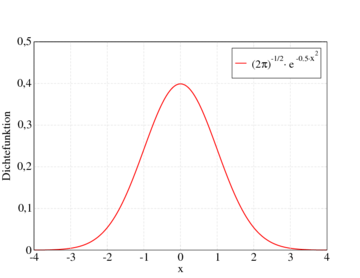 Dichtefunktion der Standardnormalverteilung
Dichtefunktion der Standardnormalverteilung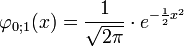
So sieht die Dichtefunktion der Standardnormalverteilung (
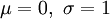 ) aus. Angegeben sind die Intervalle im Abstand 1, 2 und 3 Standardabweichungen vom Erwartungswert 0, die rund 68 %, 95,5 % und 99,7 % der Fläche unter der Glockenkurve umfassen. Die gleichen Prozentsätze gelten für alle Normalverteilungen in Bezug auf die entsprechenden Erwartungswerte und Standardabweichungen. Man beachte, dass die Dichte der Normalverteilung nie den Wert Null annimmt, das heißt es gilt f(x) > 0 für alle reellen x.
) aus. Angegeben sind die Intervalle im Abstand 1, 2 und 3 Standardabweichungen vom Erwartungswert 0, die rund 68 %, 95,5 % und 99,7 % der Fläche unter der Glockenkurve umfassen. Die gleichen Prozentsätze gelten für alle Normalverteilungen in Bezug auf die entsprechenden Erwartungswerte und Standardabweichungen. Man beachte, dass die Dichte der Normalverteilung nie den Wert Null annimmt, das heißt es gilt f(x) > 0 für alle reellen x.Die Normalverteilung ist eine Grenzverteilung, die nicht direkt beobachtet werden kann. Die Annäherung verläuft aber mit wachsendem n sehr schnell, so dass schon die Verteilung einer Summe von 30 oder 40 unabhängigen, identisch verteilten Zufallsgrößen einer Normalverteilung recht ähnlich ist.
Eigenschaften
Symmetrie
Der Graph der Wahrscheinlichkeitsdichte
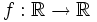 ist eine Gauß'sche Glockenkurve, deren Höhe und Breite von σ abhängt. Sie ist achsensymmetrisch zur Achse x = μ. Ihre Stammfunktion F ist Punktsymmetrisch zu P(μ | 0,5).
ist eine Gauß'sche Glockenkurve, deren Höhe und Breite von σ abhängt. Sie ist achsensymmetrisch zur Achse x = μ. Ihre Stammfunktion F ist Punktsymmetrisch zu P(μ | 0,5).Maximalwert und Wendepunkte der Dichtefunktion
Mit Hilfe der ersten und zweiten Ableitung lassen sich der Maximalwert und die Wendepunkte bestimmen. Die erste Ableitung ist
Das Maximum der Dichtefunktion der Normalverteilung liegt demnach bei xmax = μ und beträgt dort
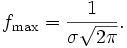
Die zweite Ableitung lautet
Somit liegen die Wendepunkte der Dichtefunktion bei
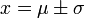 .
.Normierung
Wichtig ist, dass die gesamte Fläche unter der Kurve gleich 1 ist, also der Wahrscheinlichkeit eines sicheren Ereignisses entspricht. Somit folgt, dass, wenn zwei gaußsche Glockenkurven dasselbe μ, aber unterschiedliche σ-Werte haben, jene Kurve mit dem größeren σ breiter und niedriger ist (da ja beide zugehörigen Flächen jeweils den Wert von 1 haben und nur die Standardabweichung (oder „Streuung“) höher ist). Zwei Glockenkurven mit dem gleichen σ, aber unterschiedlichen μ haben gleich aussehende Graphen, die jedoch auf der x-Achse um die Differenz der μ-Werte zueinander verschoben sind.
Die Normierung lässt sich wie folgt nachweisen:
Wir definieren
Ist die Verteilung F normiert, so muss A = 1 gelten.
Um das Integral zu vereinfachen, verwenden wir die lineare Substitution
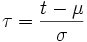 und erhalten dann wegen
und erhalten dann wegen 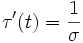
Wie erwartet ist A unabhängig von den Parametern σ und μ. Für die Normiertheit dieses Integrals siehe den Artikel Fehlerintegral.
Berechnung
Da sich das Integral der Wahrscheinlichkeitsdichtefunktion nicht auf eine elementare Stammfunktion zurückführen lässt, wurde für die Berechnung früher meist auf Tabellen zurückgegriffen (siehe dazu die Tabelle der Verteilungsfunktion der Standardnormalverteilung); heutzutage sind entsprechende Zellenfunktionen in üblichen Tabellenkalkulationsprogrammen stets verfügbar. Tabellen wie Zellenfunktionen gelten aber in der Regel nicht für beliebige μ- und σ-Werte, sondern nur für die Standardnormalverteilung, bei der μ = 0 und σ = 1 ist (man spricht auch von einer 0-1-Normalverteilung oder normierten Normalverteilung).
Die Tabellen sind also für die Wahrscheinlichkeitsverteilungsfunktion Φ (auch Gauß'sches Fehlerintegral genannt) mit
ausgelegt. Analog dazu wird die zugehörige normierte Wahrscheinlichkeitsdichtefunktion f mit φ bezeichnet.
Ist nun eine beliebige μ-σ-Verteilung gegeben, so muss diese nur in eine Standardnormalverteilung transformiert werden.
Erwartungswert
Die Normalverteilung besitzt den Erwartungswert
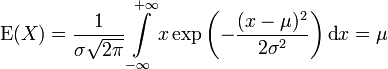 .
.
Varianz und Standardabweichung
Die Varianz ergibt sich analog zu
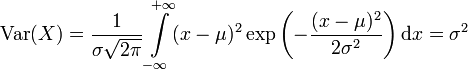 .
.
Für die Standardabweichung ergibt sich
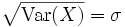 .
.
Variationskoeffizient
Aus Erwartungswert und Standardabweichung erhält man unmittelbar den Variationskoeffizienten
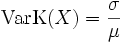 .
.
Schiefe
Die Schiefe besitzt unabhängig von den Parametern μ und σ immer den Wert 0.
Charakteristische Funktion
Die charakteristische Funktion für eine standardnormalverteilte Zufallsvariable
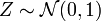 berechnet sich gemäß
berechnet sich gemäßDen Übergang von der dritten zur vierten Zeile erhält man dabei durch Anwendung des Cauchyschen Integralsatzes.
Für eine Zufallsvariable
erhält man nunwobei
.Momenterzeugende Funktion
Die momenterzeugende Funktion der Normalverteilung ist
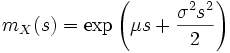 .
.
Momente
Sei X N(μ,σ2)-verteilt. Dann sind die ersten Momente wie folgt:
Nummer, k Moment, E(X^k) zentriertes Moment Kumulante 0 1 1 1 μ 0 μ 2 μ2 + σ2 σ2 σ2 3 μ3 + 3μσ2 0 0 4 μ4 + 6μ2σ2 + 3σ4 3σ4 0 5 μ5 + 10μ3σ2 + 15μσ4 0 0 6 μ6 + 15μ4σ2 + 45μ2σ4 + 15σ6 15σ6 0 7 μ7 + 21μ5σ2 + 105μ3σ4 + 105μσ6 0 0 8 μ8 + 28μ6σ2 + 210μ4σ4 + 420μ2σ6 + 105σ8 105σ8 0 Invarianz gegenüber Faltung
Die Normalverteilung ist invariant gegenüber der Faltung, d. h. die Summe unabhängiger normalverteilter Zufallsgrößen ist wieder normalverteilt. Eine veranschaulichende Formulierung dieses Sachverhaltes lautet: Die Faltung einer Gaußkurve der Halbwertsbreite Γa mit einer Gaußkurve der Halbwertsbreite Γb ergibt wieder eine Gaußkurve mit der Halbwertsbreite
Sind also X,Y zwei unabhängige Zufallsvariable mit
so ist deren Summe ebenfalls normalverteilt:
Das lässt sich dadurch beweisen, dass die charakteristische Funktion der Summe das Produkt der charakteristischen Funktionen der Summanden ist.
Speziell ist das arithmetische Mittel n unabhängiger und normalverteilter Zufallsgrößen
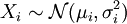 wieder eine normalverteilte Zufallsgröße mit
wieder eine normalverteilte Zufallsgröße mitNach dem Satz von Cramér gilt sogar die Umkehrung: Ist eine normalverteilte Zufallsgröße die Summe von unabhängigen Zufallsgrößen, dann sind die Summanden ebenfalls normalverteilt.
Die Dichtefunktion der Normalverteilung ist ein Fixpunkt der Fourier-Transformation, d. h. die Fourier-Transformierte einer Gaußkurve ist wieder eine Gaußkurve. Das Produkt der Standardabweichungen dieser korrespondierenden Gaußkurven ist konstant; es gilt die heisenbergsche Unschärferelation.
Entropie
Die Normalverteilung hat die Entropie:
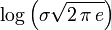 .
.Da sie für eine gegebene Varianz die größte Entropie unter allen Verteilungen hat, wird sie in der Maximum-Entropie-Methode oft als a-priori-Wahrscheinlichkeit verwendet.
Mehrdimensionale Verallgemeinerung
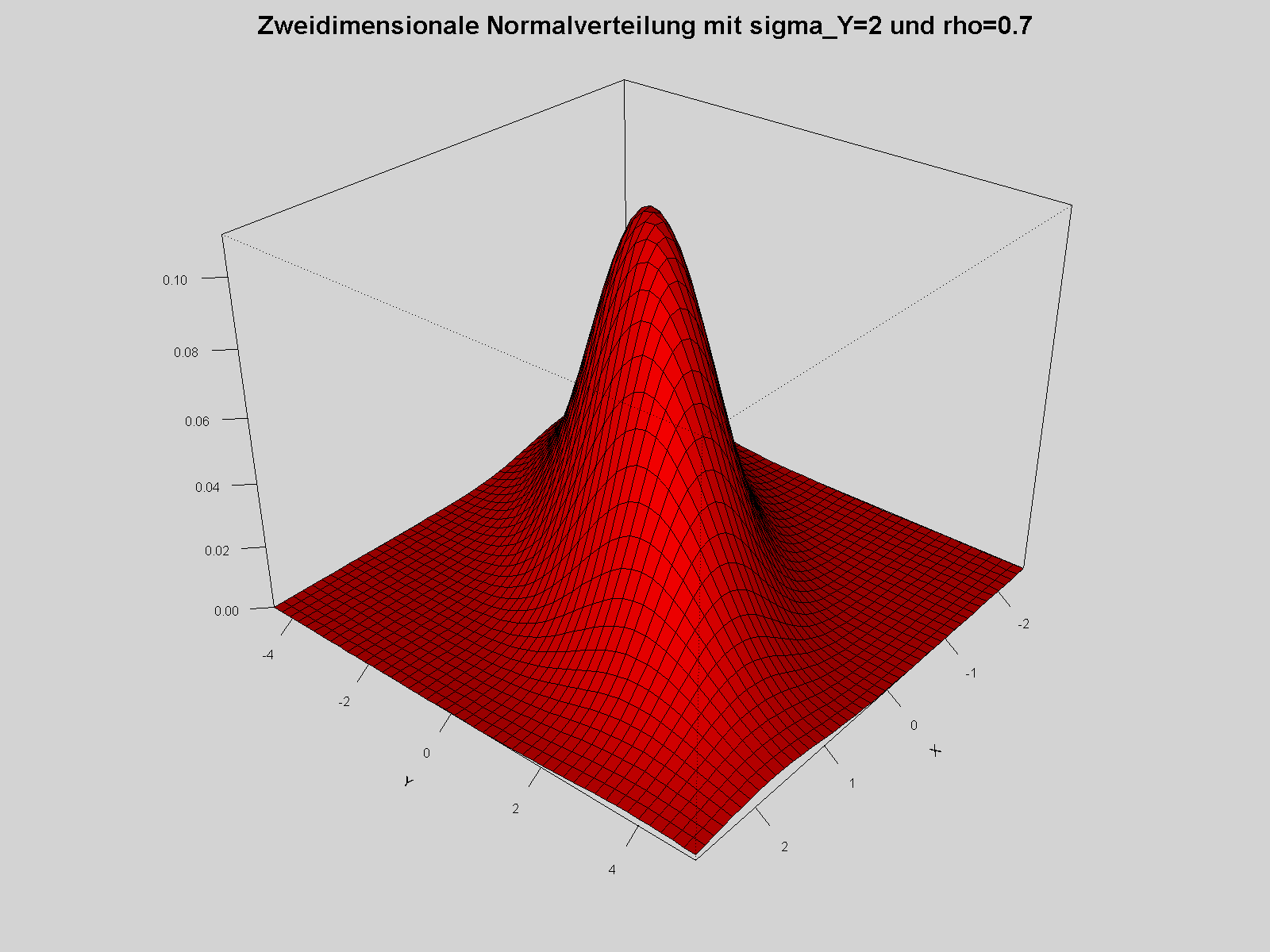
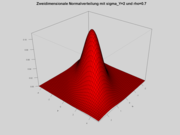 Dichte der zweidimensionalen Normalverteilung; die Standardabweichung der zweiten Koordinate Y ist 2, die Korrelation zwischen den Koordinaten 0,7
Dichte der zweidimensionalen Normalverteilung; die Standardabweichung der zweiten Koordinate Y ist 2, die Korrelation zwischen den Koordinaten 0,7Das Wahrscheinlichkeitsmaß
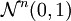 auf
auf 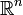 , das durch die Dichtefunktion
, das durch die Dichtefunktiondefiniert wird, heißt Standardnormalverteilung der Dimension n. Ein Zufallsvektor
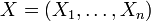 ist genau dann standardnormalverteilt auf , wenn seine Komponenten
ist genau dann standardnormalverteilt auf , wenn seine Komponenten 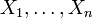 standardnormalverteilt und stochastisch unabhängig sind.
standardnormalverteilt und stochastisch unabhängig sind.Die multivariate Standardnormalverteilung ist abgesehen von Translationen (d. h. Erwartungswert
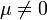 ) die einzige multivariate Verteilung, deren Komponenten stochastisch unabhängig sind und deren Dichte zugleich rotationssymmetrisch ist.
) die einzige multivariate Verteilung, deren Komponenten stochastisch unabhängig sind und deren Dichte zugleich rotationssymmetrisch ist.Ein Wahrscheinlichkeitsmaß P auf
heißt n-dimensionale Normalverteilung, wenn eine Matrix 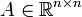 und ein Vektor
und ein Vektor 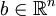 existieren, sodass mit der affinen Abbildung
existieren, sodass mit der affinen Abbildung 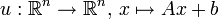 gilt:
gilt:Die Dichtefunktion der zweidimensionalen Normalverteilung mit einem Korrelationskoeffizienten
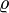 ist
istund schließlich im n-dimensionalen Fall
mit | Σ | als der Determinante der Kovarianzmatrix Σ.
Beziehungen zu anderen Verteilungsfunktionen
Transformation zur Standardnormalverteilung (z-Transformation)
Ist eine Normalverteilung mit beliebigen μ und σ gegeben, so kann diese durch eine Transformation auf eine
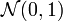 -Normalverteilung zurückgeführt werden. Dazu wird die Verteilungsfunktion F(x) der allgemeinen Normalverteilung mit
-Normalverteilung zurückgeführt werden. Dazu wird die Verteilungsfunktion F(x) der allgemeinen Normalverteilung mit 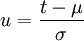 substituiert und die Integralgrenzen werden angepasst:
substituiert und die Integralgrenzen werden angepasst:Nebenrechnung für die Substitution 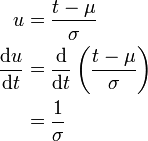
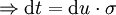
Wird nun
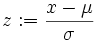 definiert und u durch t ersetzt, so erhält man die Verteilungsfunktion der Standardnormalverteilung:
definiert und u durch t ersetzt, so erhält man die Verteilungsfunktion der Standardnormalverteilung:Geometrisch betrachtet entspricht die durchgeführte Substitution einer flächentreuen Transformation der Glockenkurve von
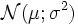 zur Glockenkurve von
zur Glockenkurve von 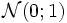 .
.Approximation der Binomialverteilung durch die Normalverteilung
Die Normalverteilung kann zur Approximation der Binomialverteilung verwendet werden, wenn der Stichprobenumfang n hinreichend groß und in der Grundgesamtheit der Anteil p der gesuchten Eigenschaft nicht zu klein ist. Als Faustregeln dafür gelten:
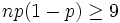 , was für die Standardabweichung bedeutet:
, was für die Standardabweichung bedeutet: 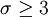
Falls diese Bedingung nicht erfüllt sein sollte, ist die Näherung immer noch vertretbar genau, wenn gilt:
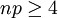 und zugleich
und zugleich 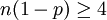 .
.Ist eine Binomialverteilung (Bernoulli-Versuch) mit n voneinander unabhängigen Stufen (bzw. Zufallsversuchen) mit einer Erfolgswahrscheinlichkeit p gegeben, so lässt sich die Wahrscheinlichkeit für k Erfolge allgemein durch
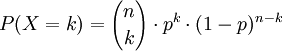 für
für 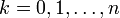 berechnen.
berechnen.Für sehr große Werte von n kann diese Binomialverteilung durch eine Normalverteilung approximiert werden (Satz von Moivre-Laplace, zentraler Grenzwertsatz). Dabei ist
- der Erwartungswert
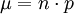
- und die Standardabweichung
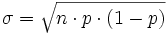
Ist nun σ > 3, dann ist folgende Näherung brauchbar:
Bei der Normalverteilung wird die untere Grenze um 0,5 verkleinert und die obere Grenze um 0,5 vergrößert, um eine bessere Approximation bei einer geringen Standardabweichung σ gewährleisten zu können. Dies nennt man auch Stetigkeitskorrektur. Nur wenn σ einen sehr hohen Wert besitzt, kann auf sie verzichtet werden.
Da die Binomialverteilung diskret ist, muss auf einige Punkte geachtet werden:
- < oder
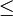 (und auch größer und größer gleich) müssen beachtet werden (was ja bei der Normalverteilung nicht der Fall ist). Deshalb muss bei P(XBV < x) die nächstkleinere natürliche Zahl gewählt werden, d. h.
(und auch größer und größer gleich) müssen beachtet werden (was ja bei der Normalverteilung nicht der Fall ist). Deshalb muss bei P(XBV < x) die nächstkleinere natürliche Zahl gewählt werden, d. h.
-
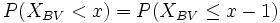 bzw.
bzw. 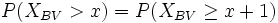
- damit mit der Normalverteilung weitergerechnet werden kann.
- z. B.
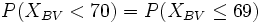
- Außerdem ist
-
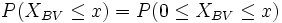
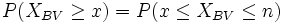
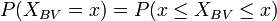 (unbedingt mit Stetigkeitskorrektur)
(unbedingt mit Stetigkeitskorrektur)
- und lässt sich somit durch die oben angegebene Formel berechnen.
Der große Vorteil der Approximation liegt darin, dass sehr viele Stufen einer Binomialverteilung sehr schnell und einfach bestimmt werden können.
Beziehung zur Cauchy-Verteilung
Der Quotient von zwei unabhängigen
standardnormalverteilten Zufallsvariablen ist Cauchy-verteilt.Beziehung zur Chi-Quadrat-Verteilung
- Die Summe
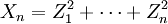 von n unabhängigen quadrierten standardnormalverteilten Zufallsvariablen
von n unabhängigen quadrierten standardnormalverteilten Zufallsvariablen 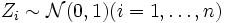 genügt einer Chi-Quadrat-Verteilung
genügt einer Chi-Quadrat-Verteilung 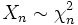 mit n Freiheitsgraden.
mit n Freiheitsgraden.
- Die Summe
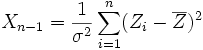 mit
mit 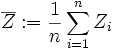 und n unabhängigen normalverteilten Zufallsvariablen
und n unabhängigen normalverteilten Zufallsvariablen 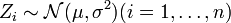 genügt einer Chi-Quadrat-Verteilung
genügt einer Chi-Quadrat-Verteilung 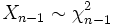 mit n − 1 Freiheitsgraden.
mit n − 1 Freiheitsgraden.
Die Chi-Quadrat-Verteilung wird zur Konfidenzschätzung für die Varianz einer normalverteilten Grundgesamtheit verwendet.
Beziehung zur Rayleigh-Verteilung
Der Betrag
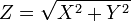 zweier normalverteilter Zufallsvariablen X,Y ist Rayleigh-verteilt.
zweier normalverteilter Zufallsvariablen X,Y ist Rayleigh-verteilt.Beziehung zur logarithmischen Normalverteilung
Ist die Zufallsvariable X normalverteilt mit
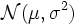 , dann ist die Zufallsvariable Y = eX logarithmisch-normalverteilt mit
, dann ist die Zufallsvariable Y = eX logarithmisch-normalverteilt mit 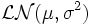 .
.Die Entstehung einer logarithmischen Normalverteilung ist auf multiplikatives, die einer Normalverteilung auf additives Zusammenwirken vieler Zufallsgrößen zurückführen.
Beziehung zur F-Verteilung
Wenn die identischen normalverteilten Zufallsvariablen
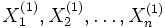 und
und 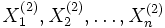 die Parameter
die Parametermit σ1 = σ2 = σ besitzen, dann unterliegt die Zufallsvariable
einer F-Verteilung mit ((n1 − 1,n2 − 1)) Freiheitsgraden. Dabei sind
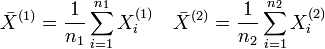 .
.
Beziehung zur Student-t-Verteilung
Wenn die unabhängigen Zufallsvariablen
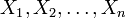 identisch normalverteilt sind mit den Parametern μ und σ, dann unterliegt die stetige Zufallsgröße
identisch normalverteilt sind mit den Parametern μ und σ, dann unterliegt die stetige Zufallsgrößeeiner Student-t-Verteilung mit (n − 1) Freiheitsgraden.
Die Student-t-Verteilung wird zur Konfidenzschätzung für den Erwartungswert einer normalverteilten Zufallsvariable bei unbekannter Varianz verwendet.
Rechnen mit der Standardnormalverteilung
Bei Aufgabenstellungen, bei denen die Wahrscheinlichkeit für normalverteilte Zufallsvariablen durch die Standardnormalverteilung ermittelt werden soll, ist es nicht nötig, die oben angegebene Transformation jedes Mal durchzurechnen. Stattdessen wird einfach das Ergebnis der Transformation verwendet, um die Grenzen x1, x2 und die Zufallsvariable X auf die Grenzen z1, z2 und die Zufallsvariable Z anzugleichen. Somit kann eine
Verteilung durch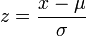 beziehungsweise
beziehungsweise 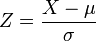
zu
transformiert werden.Die Wahrscheinlichkeit für ein Ereignis, welches z. B. innerhalb der Werte x1 und x2 (für den Erwartungswert μ und die Standardabweichung σ) liegt, ist durch folgende Umrechnung gleich der Wahrscheinlichkeit der Standardnormalverteilung mit den neuen Grenzen z1 und z2:
P steht für die englische Bezeichnung „probability“ oder das französische Wort „probabilité“ der Wahrscheinlichkeit.
Grundlegende Fragestellungen
Allgemein gibt die Verteilungsfunktion die Fläche unter der Glockenkurve bis zum Wert x an, d. h. es wird das bestimmte Integral von
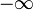 bis x berechnet.
bis x berechnet.Dies entspricht in Aufgabenstellungen einer gesuchten Wahrscheinlichkeit, bei der die Zufallsvariable X kleiner oder kleiner gleich einer bestimmten Zahl x ist. Durch die Verwendung der reellen Zahlen und der Stetigkeit der Normalverteilung macht es keinen Unterschied, ob nun < oder
verlangt ist,- weil
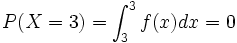 und somit
und somit 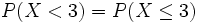 .
.
Dasselbe gilt für größer und größer gleich.
Dadurch, dass X nur kleiner oder größer einer Grenze (oder innerhalb oder außerhalb zweier Grenzen) liegen kann, ergeben sich für Aufgaben bei normalverteilten Wahrscheinlichkeitsberechnungen folgende zwei grundlegende Fragestellungen:
- Wie hoch ist die Wahrscheinlichkeit, dass bei einem Zufallsversuch die normalverteilte Zufallsvariable Z höchstens den Wert z annimmt?
- In der Schulmathematik wird für diese Aussage auch die Bezeichnung Linker Spitz verwendet, da die Fläche unter der Gaußkurve von links bis zur Grenze verläuft. Für z sind auch negative Werte erlaubt, trotzdem haben viele Tabellen der Standardnormalverteilung nur positive Einträge. Durch die Symmetrie der Kurve und der Negativitätsregel des linken Spitz stellt dies aber keine Einschränkung dar:
- Wie hoch ist die Wahrscheinlichkeit, dass bei einem Zufallsversuch die normalverteilte Zufallsvariable Z mindestens den Wert z annimmt?
-
- Analog wird hier oft die Bezeichnung Rechter Spitz verwendet. Ebenso gibt es eine Negativitätsregel:
(Da jede Zufallsvariable X der allgemeinen Normalverteilung sich in die Zufallsgröße Z der Standardnormalverteilung umwandeln lässt, gelten die Fragestellungen für beide Größen gleichbedeutend.)
Streubereich und Antistreubereich
Der Streubereich gibt die Wahrscheinlichkeit wieder, dass die normalverteilte Zufallsvariable Z Werte zwischen z1 und z2 annimmt:
Beim Sonderfall des symmetrischen Streubereiches (z1 = − z2, mit z2 > 0) gilt
Hingegen gibt der Antistreubereich die Höhe der Wahrscheinlichkeit an, dass die normalverteilte Zufallsvariable Z Werte außerhalb des Bereichs zwischen z1 und z2 annimmt:
Somit folgt bei einem symmetrischen Antistreubereich
Streubereiche am Beispiel der Qualitätssicherung
Besondere Bedeutung haben beide Streubereiche z. B. bei der Qualitätssicherung von technischen oder wirtschaftlichen Produktionsprozessen. Hier gibt es einzuhaltende Toleranzgrenzen x1 und x2 , wobei es meist einen größten noch akzeptablen Abstand ε vom Erwartungswert μ (= dem optimalen Sollwert) gibt. σ kann hingegen empirisch aus dem Produktionsprozess gewonnen werden.
Wurde [x1;x2] = [μ − ε;μ + ε] als einzuhaltendes Toleranzintervall angegeben, so liegt (je nach Fragestellung) ein symmetrischer Streu- oder Antistreubereich vor.
Im Falle des Streubereiches gilt:
Der Antistreubereich ergibt sich dann aus
oder wenn kein Streubereich berechnet wurde durch
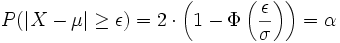 .
.
Das Ergebnis γ ist also die Wahrscheinlichkeit für verkaufbare Produkte, während α die Wahrscheinlichkeit für Ausschuss bedeutet, wobei beides von den Vorgaben von μ, σ und ε abhängig ist.
Ist bekannt, dass die maximale Abweichung ε symmetrisch um den Erwartungswert liegt, so sind auch Fragestellungen möglich, bei denen die Wahrscheinlichkeit vorgegeben und eine der anderen Größen zu berechnen ist.
Testen auf Normalverteilung
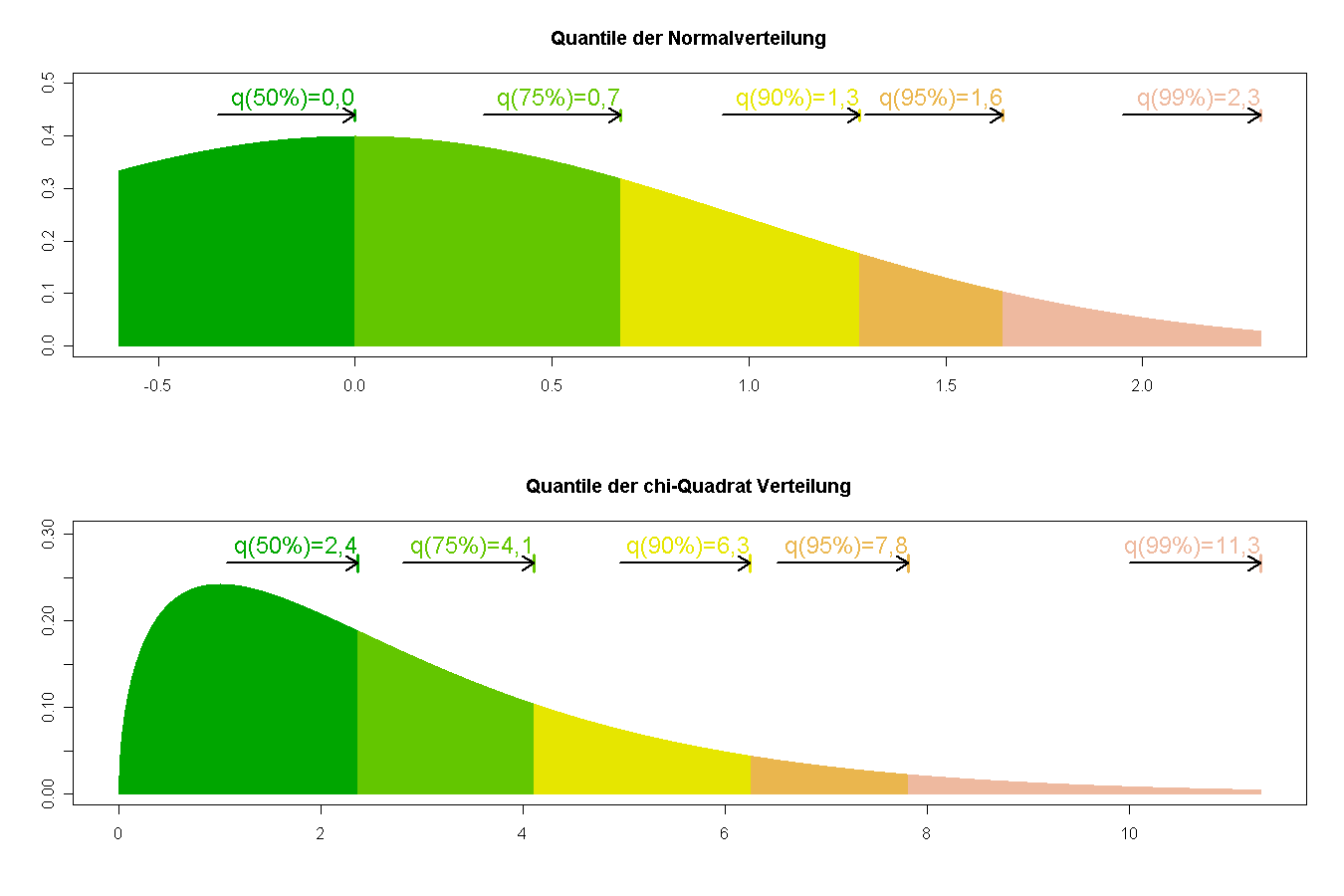
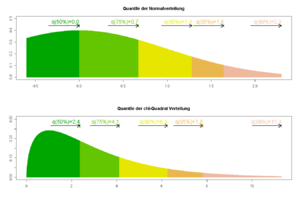 Quantile einer Normalverteilung und einer Chi-Quadrat-Verteilung
Quantile einer Normalverteilung und einer Chi-Quadrat-VerteilungUm zu überprüfen, ob vorliegende Daten normalverteilt sind, können folgende Methoden angewandt werden:
- Chi-Quadrat-Test
- Kolmogorov-Smirnov-Test
- Anderson-Darling-Test (Modifikation des Kolmogorov-Smirnov-Tests)
- Lilliefors-Test (Modifikation des Kolmogorov-Smirnov-Tests)
- Shapiro-Wilk-Test
- Jarque-Bera-Test
- Q-Q-Plot (deskriptive Überprüfung)
- Maximum-Likelihood-Methode (deskriptive Überprüfung)
Die Tests haben unterschiedliche Eigenschaften hinsichtlich der Art der Abweichungen von der Normalverteilung, die sie erkennen. So erkennt der Kolmogorov-Smirnov-Test Abweichungen in der Mitte der Verteilung eher als Abweichungen an den Rändern, während der Jarque-Bera-Test ziemlich sensibel auf stark abweichende Einzelwerte an den Rändern („heavy tails“) reagiert.
Beim Lilliefors-Test muss im Gegensatz zum Kolomogorov-Smirnov-Test nicht standardisiert werden, d. h. μ und σ der angenommenen Normalverteilung dürfen unbekannt sein.
Mit Hilfe von Quantil-Quantil-Plots (auch Normal-Quantil-Plots oder kurz Q-Q-Plot) ist eine einfache grafische Überprüfung auf Normalverteilung möglich.
Mit der Maximum-Likeliehood-Methode können die Parameter μ und σ der Normalverteilung geschätzt und die empirischen Daten mit der angepassten Normalverteilung grafisch verglichen werden.Simulation normalverteilter Zufallsvariablen
Box-Muller-Methode
Nach der Box-Muller-Methode lässt sich eine standardnormalverteilte Zufallsvariable X aus zwei gleichverteilten Zufallsvariablen
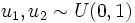 , sogenannten Standardzufallszahlen, simulieren:
, sogenannten Standardzufallszahlen, simulieren:Polar-Methode
Die Polar-Methode von Marsaglia ist auf einem Computer noch schneller, da sie nur einen Logarithmus benutzt:
- Erzeuge zwei voneinander unabhängige, im Intervall [ − 1,1] gleichverteilte Zufallszahlen u1,u2
- Berechne
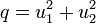 . Falls q > 1, wiederhole Schritt 1.
. Falls q > 1, wiederhole Schritt 1. - Berechne
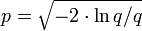
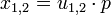 liefert zwei voneinander unabhängige, standardnormalverteilte Zufallszahlen x1,2.
liefert zwei voneinander unabhängige, standardnormalverteilte Zufallszahlen x1,2.
Durch lineare Transformation lassen sich hieraus beliebige normalverteilte Zufallszahlen erzeugen: Ist die Zufallsvariable
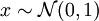 -verteilt, so ist
-verteilt, so ist 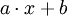 schließlich
schließlich 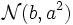 -verteilt.
-verteilt.Zwölferregel
Der zentrale Grenzwertsatz besagt, dass sich unter bestimmten Voraussetzungen die Verteilung der Summe unabhängiger, identisch verteilter Zufallszahlen einer Normalverteilung nähert.
Ein Spezialfall ist die Zwölferregel, die sich auf die Summe von zwölf Zufallszahlen aus einer Gleichverteilung auf dem Intervall [0,1] beschränkt und bereits zu passablen Verteilungen führt.
Stark ins Gewicht fällt die Forderung der Unabhängigkeit der zwölf Zufallsvariablen Xi, die bei normalen Pseudozufallszahlen (LKG) nicht garantiert ist. Im Gegenteil wird vom Spektraltest meist nur die Unabhängigkeit von maximal vier bis sieben der Xi garantiert. Für numerische Simulationen ist die Zwölferregel daher sehr bedenklich. Andere, sogar leichter zu programmierende Verfahren, sind daher vorzuziehen.
Verwerfungsmethode
Normalverteilungen lassen sich mit der Verwerfungsmethode (s. dort) simulieren.
Inversionsmethode
Die Normalverteilung lässt sich auch mit der Inversionsmethode berechnen. Da das Fehlerintegral leider nicht explizit mit elementaren Funktionen integrierbar ist, muss man auf Reihenentwicklungen der inversen Funktion für einen Startwert (a1...a14 weiter unten) und anschließende Korrektur mit dem Newtonverfahren zurückgreifen. Dazu werden erf(x) und erfc(x) benötigt, die ihrerseits mit Reihenentwicklungen und Kettenbruchentwicklungen berechnet werden können - insgesamt ein relativ hoher Aufwand. Die notwendigen Entwicklungen sind in der Literatur zu finden.[2]
Entwicklung des inversen Fehlerintegrals (wegen des Pols nur als Startwert für das Newtonverfahren verwendbar):
mit den Koeffizienten
Simulation mehrdimensionaler normalverteilter Zufallsvektoren
Die Komponenten des Zufallsvektors X * werden durch standardnormalverteilte Zufallsvariable gefüllt (diese lassen sich mit einem der obigen Verfahren erzeugen). Dann ist der Zufallsvektor
-
- X = UX * + μ
eine Realisierung der Normalverteilung mit Erwartungswertvektor μ und Kovarianzmatrix
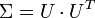 . U wird dabei durch die Cholesky-Zerlegung berechnet.
. U wird dabei durch die Cholesky-Zerlegung berechnet.Plausibilisierung:
Erwartungswert:
Kovarianz:
Anwendungen außerhalb der Wahrscheinlichkeitsrechnung
Die Normalverteilung lässt sich auch zur Beschreibung nicht direkt stochastischer Sachverhalte verwenden, etwa in der Physik für das Amplitudenprofil der Gauß-Strahlen und andere Verteilungsprofile.
Zudem findet sie Verwendung in der Gabor-Transformation.
Siehe auch
Quellen
- ↑ Bei der Funktion exp(x) handelt es sich um die Exponentialfunktion mit der Basis e, auch als ex bekannt.
- ↑ William B. Jones, W. J. Thron; Continued Fractions: Analytic Theory and Applications; Addison Wesley, 1980
Weblinks
Diskrete univariate VerteilungenDiskrete univariate Verteilungen für endliche Mengen:
Benford | Bernoulli-Verteilung | Binomialverteilung | Kategoriale | Hypergeometrische Verteilung | Rademacher | Zipfsche | Zipf-MandelbrotDiskrete univariate Verteilungen für unendliche Mengen:
Boltzmann | Conway-Maxwell-Poisson | Negative Binomialverteilung | Erweiterte negative Binomial | Compound Poisson | Diskret uniform | Discrete phase-type | Gauss-Kuzmin | Geometrische | Logarithmische | Parabolisch-fraktale | Poisson | Skellam | Yule-Simon | ZetaKontinuierliche univariate VerteilungenKontinuierliche univariate Verteilungen mit kompaktem Intervall:
Beta | Kumaraswamy | Raised Cosine | Dreiecks | U-quadratisch | Stetige Gleichverteilung | Wigner-HalbkreisKontinuierliche univariate Verteilungen mit halboffenem Intervall:
Beta prime | Bose-Einstein | Burr | Chi-Quadrat | Coxian | Erlang | Exponential | F | Fermi-Dirac | Folded Normal | Fréchet | Gamma | Extremwert | Verallgemeinerte inverse Gausssche | Halblogistische | Halbnormale | Hotellings T-Quadrat | hyper-exponentiale | hypoexponential | Inverse Chi-Quadrat | Scale Inverse Chi-Quadrat | Inverse Normal | Inverse Gamma | Lévy | Log-normal | Log-logistische | Maxwell-Boltzmann | Maxwell speed | Nakagami | nichtzentrierte Chi-Quadrat | Pareto | Phase-type | Rayleigh | relativistische Breit-Wigner | Rice | Rosin-Rammler | Shifted Gompertz | Truncated Normal | Type-2-Gumbel | Weibull | Wilks’ lambdaKontinuierliche univariate Verteilungen mit unbeschränktem Intervall:
Cauchy | Extremwert | Exponential Power | Fisher’s z | Fisher-Tippett (Gumbel) | Generalized Hyperbolic | Hyperbolic Secant | Landau | Laplace | Alpha stabile | logistisch | Normal (Gauss) | Normal-inverse Gausssche | Skew normal | Studentsche t | Type-1 Gumbel | Variance-Gamma | VoigtMultivariate VerteilungenDiskrete multivariate Verteilungen:
Ewen's | Multinomial | Dirichlet MultinomialKontinuierliche multivariate Verteilungen:
Dirichlet | Generalized Dirichlet | Multivariate Normal | Multivariate Student | Normalskalierte inverse Gamma | Normal-GammaMultivariate Matrixverteilungen:
Inverse-Wishart | Matrix Normal | Wishart
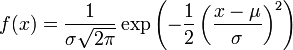
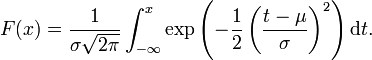
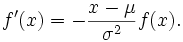
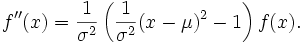
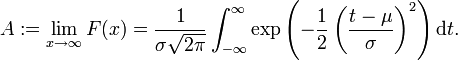
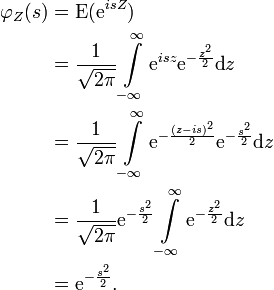
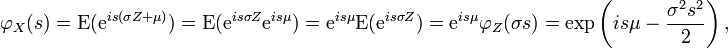
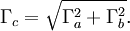
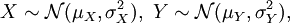
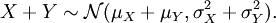
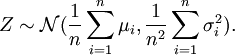
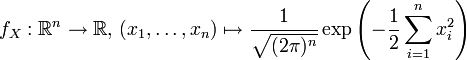
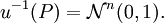
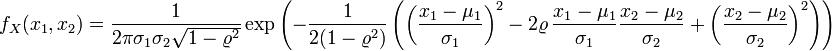
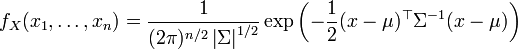
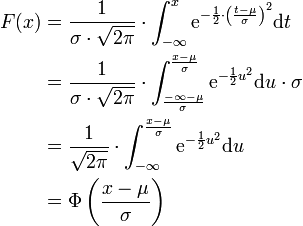
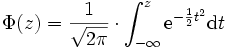
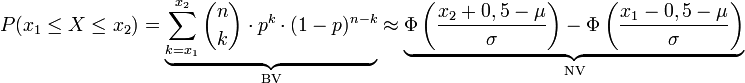
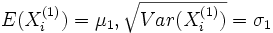
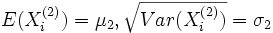
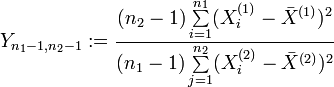
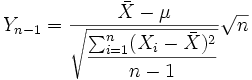
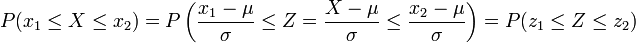
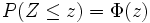
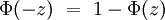
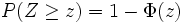
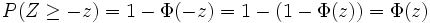
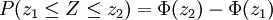
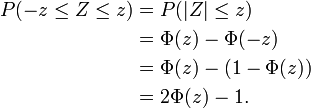
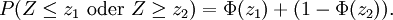
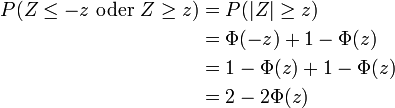
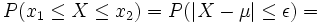
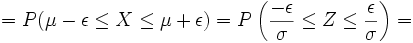
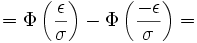
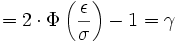
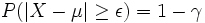
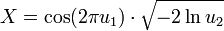
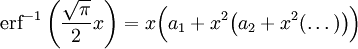

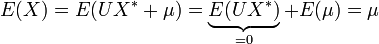
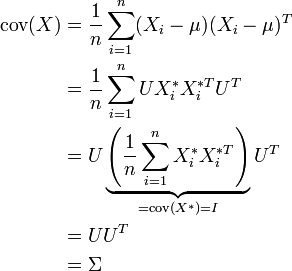
Wikimedia Foundation.