- Fleiss' Kappa
-
Cohens Kappa ist ein statistisches Maß für die Interrater-Reliabilität von Einschätzungen von (in der Regel) zwei Beurteilern (Ratern), das Jacob Cohen 1960 vorschlug.
Die Gleichung für Cohens Kappa lautet
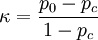
wobei p0 der gemessene Übereinstimmungswert der beiden Schätzer und pc die zufällig erwartete Übereinstimmung ist. Wenn die Rater in allen ihren Urteilen übereinstimmen, ist κ = 1. Sofern sich nur Übereinstimmungen zwischen den beiden Ratern feststellen lassen, die mathematisch dem Ausmaß des Zufalls entsprechen, nimmt es einen Wert von κ = 0 an. (Negative Werte weisen dagegen auf eine Übereinstimmung hin, die noch kleiner ist als eine zufällige Übereinstimmung.)
Greve und Wentura (1997, S. 111) berichten von verschiedenen Einschätzungen hinsichtlich des κ-Wertes. Als Resümee lässt sich festhalten, dass κ-Werte von 0,40 bis 0,60 vielleicht noch annehmbar sind, aber Werte unter 0,40 mit etwas Skepsis betrachtet werden sollten. Interrater-Reliabilitätswerte von κ>=0,75 scheinen gut bis ausgezeichnet.
Landis und Koch (1977) schlagen dagegen folgende Werte vor: κ<0 = „schlechte Übereinstimmung (poor agreement)“, κ zwischen 0 und 0,20 = „etwas (slight) Übereinstimmung“, 0,21-0,40 = „ausreichende (fair) Übereinstimmung“, 0,41-0,60 = „mittelmäßige (moderate) Übereinstimmung“, 0,61-0,80 = „beachtliche (substantial) Übereinstimmung“, 0,81-1,00 = „(fast) vollkommene ((almost) perfect) Übereinstimmung“.
Problematisch am Koeffizienten ist insbesondere, dass sein maximaler Wert nicht immer und automatisch 1,00 ist (s. u.).
Inhaltsverzeichnis
Nominalskalen, zwei Rater
Wenn lediglich Übereinstimmungen und Nicht-Übereinstimmungen zwischen den beiden Ratern abgeprüft werden, fallen alle auftretenden Beurteilungsunterschiede gleich ins Gewicht. Dies ist insbesondere bei Nominalskalen sinnvoll. Dabei kann das Datenmaterial (also die Urteilshäufigkeiten h) bei einem Item oder Merkmal mit z (nominalen) Kategorien Kat von beiden Einschätzern in einer zxz Kontingenztafel (also mit z Zeilen und z Spalten) abgetragen werden:
Rater B Randhäufigkeiten hi. Rater A Kat1 ... Katz 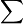
Kat1 h11 ... h1z 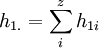
. . ... . . . . ... . . . . ... . . Katz hz1 ... hzz 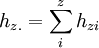
Randhäufigkeiten h.i 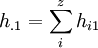
... 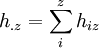
Dann gilt für den Anteil der übereinstimmenden Einschätzungen der Rater (= Mitteldiagonale der Kontingenztafel) p0:
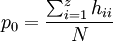 ,
,wobei N gleich der Anzahl der insgesamt eingeschätzten Beurteilungsobjekte (Personen/Items/Gegenstände) entspricht.
Für die erwarteten Übereinstimmungen werden die Produkte der Randsummen (=Zeilensumme x Spaltensumme) einer Kategorie Kat aufsummiert und schließlich ins Verhältnis zum Quadrat der Gesamtsumme gesetzt: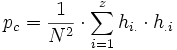 .
.Scott (1955) schlug für seinen Koeffizienten π, der nach derselben Ausgangsformel wie κ berechnet wird, vor, die erwarteten Übereinstimmungen wie folgt zu bestimmen:
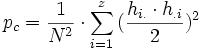 .
.Sofern die Randverteilungen unterschiedlich sind, ist Scotts π immer größer als Cohens κ.
Sobald in der Kontingenztafel auch nur eine Zelle jenseits der Diagonalen gefüllt ist (also Beurteilungsunterschiede auftreten), hängt der maximale Wert von Cohens Kappa von den Randverteilungen ab. Er wird umso geringer, je weiter sich die Randverteilungen von einer Gleichverteilung entfernen. Brennan und Prediger (1981) schlagen hier einen korrigierten Kappa-Wert κn vor, der pc definiert als
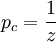 , wobei z wie oben die Anzahl der Kategorien (also der Merkmalsausprägungen) ist. Somit lautet κn:
, wobei z wie oben die Anzahl der Kategorien (also der Merkmalsausprägungen) ist. Somit lautet κn: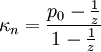
Fleiss' Kappa
Die Ausweitung der Formeln auf mehr als zwei Rater ist im Prinzip unproblematisch. Die Ausweitung der κ-Statistik wird auch als Fleiss' Kappa bezeichnet. Für den Anteil der aufgetretenen Übereinstimmungen gilt dann z. B. für drei Rater
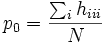 und
und 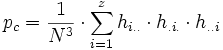 .
.Für den Koeffizienten von Brennan und Prediger (1981) schlägt von Eye (2006, S. 15) folgende Ausweitung auf d Rater vor:
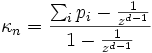 wobei i ein Index für die Übereinstimmungszellen (Diagonalen) ist.
wobei i ein Index für die Übereinstimmungszellen (Diagonalen) ist.Wenn z wie oben die Anzahl der Kategorien (j = 1,2,3,...z) ist und d die Anzahl der Rater (= Anzahl der Einschätzungen pro Merkmal/Item/Person) und wobei N die Anzahl der insgesamt eingeschätzten Beurteilungsobjekte (Fälle/Personen/Items/Gegenstände) i = 1,2,3,...N ist, gilt folgendes:
- dij ist die Anzahl der Rater, die Beurteilungsobjekt i in Kategorie j passend beurteilt hat.
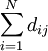 ist die Summe aller Fälle in Beurteilungskategorie j.
ist die Summe aller Fälle in Beurteilungskategorie j.
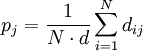 ist der Anteil aller Fälle in Beurteilungskategorie j an allen (
ist der Anteil aller Fälle in Beurteilungskategorie j an allen (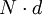 ) Beurteilungen insgesamt.
) Beurteilungen insgesamt.
Das Ausmaß der Beurteilerübereinstimmung beim i. Fall (=bei der i. Person/Item/Gegenstand) berechnet sich dann als
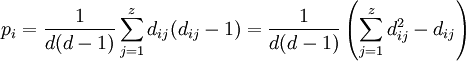
In die κ-Formel fließt der Mittelwert über alle pi ein sowie der Erwartungswert für den Zufall pc ein:
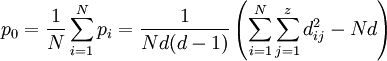
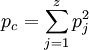 .
.1 2 3 4 5 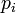
1 0 0 0 0 14 1.000 2 0 2 6 4 2 0.253 3 0 0 3 5 6 0.308 4 0 3 9 2 0 0.440 5 2 2 8 1 1 0.330 6 7 7 0 0 0 0.462 7 3 2 6 3 0 0.242 8 2 5 3 2 2 0.176 9 6 5 2 1 0 0.286 10 0 2 2 3 7 0.286 Gesamt 20 28 39 21 32 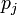
0.143 0.200 0.279 0.150 0.229 Beispieltafel zur Berechnung von Fleiss' Kappa Beispiel
Im folgenden Rechenbeispiel (aus englischem Artikel) beurteilen d = 14 Rater jeweils N = 10 Fälle auf einer Skala mit z = 5 Kategorien.
Die Kategorien finden sich in den Spalten, die Fälle in den Zeilen. Die Summe aller Beurteilungen
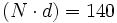 .
.Beispielsweise ist pj in der ersten Spalte
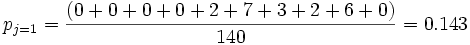
undpi in der zweiten Zeile
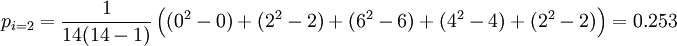
So ergibt sich für
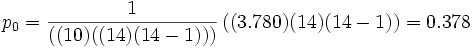
pc = 0.1432 + 0.2002 + 0.2792 + 0.1502 + 0.2292 = 0.211 und
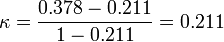
(Dass hier κ so ähnlich ist wie pc ist Zufall.)
Mehrfachstufung der Meßobjekte, zwei Rater
Sind die Rater aber aufgefordert, die Schätzobjekte mehrfach zu stufen (d. h. statt der k nominalen Kategorien geht es nun um Abstufungen und kann für diese Abstufungen mindestens ein Ordinal-Skalenniveau angenommen werden), sollten aber diskonkordant größere Abweichungen der Rater voneinander stärker ins Gewicht fallen als kleinere Abweichungen. In diesem Fall sollten ein gewichtetes Kappa berechnet werden, bei dem für jede Zelle ij der Kontingenztafel ein Gewichtungsfaktor vij definiert wird, das sich z. B. daran orientieren könnte, wie groß die Abweichung von der Mitteldiagonalen ist (z. B. als quadrierte Abweichungen Mitteldiagonalzellen=0, Abweichungen um 1 Kategorie=1, Abweichungen um 2 Kategorien=22=4 usw.). Dann gilt für dieses (gewichtete) Kappa κw(vgl. Bortz 1999):
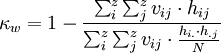
Alternativen zu diesem Koeffizienten sind der Rangkorrelationskoeffizient nach Spearman und Kendall's Tau sowie Kendalls Konkordanzkoeffizient W.
Kardinalskalen-Kappa
Dieser Gewichtungsgedanke lässt sich auch weiterführen: Auf Intervall-Skalenniveau ist das Ausmaß des Unterschieds (bzw. der Ähnlichkeit) zwischen den abgegebenen Einschätzungen sogar direkt quantifizierbar (Cohen 1968, 1972). Die Gewichtungswerte für jede Zelle der Kontingenztafel orientieren sich dann jeweils am maximalen und minimalem Unterschied.
Für das Kardinalskalen-κ gilt, dass identische Einschätzungen (bzw. der Minimalunterschied zwischen Beobachtern standardisiert mit dem Wert 0 und der maximale Beobachterunterschied mit einen Wert von 1 gewichtet werden sollen (und die anderen beobachteten Unterschiede jeweils in ihrem Verhältnis dazu):
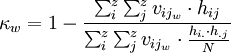
und für die [0,1]-Standardisierung der Gewichte:
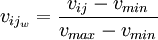 .
.Das gewichtete Kappa ist ein Spezialfall des Intraklassen-Korrelationskoeffizienten (Fleiss & Cohen 1973).
Literatur und Quellen
- J. Bortz: Statistik für Sozialwissenschaftler. 5. Auflage. Springer, Berlin 1999.
- J. Bortz, G. A. Lienert, K. Boehnke: Verteilungsfreie Methoden in der Biostatistik. Kapitel 9. Springer, Berlin 1990.
- R. L. Brennan, D. J. Prediger: Coefficient κ: Some uses, misuses, and alternatives. In: Educational and Psychological Measurement. 41, 1981, 687–699.
- J. Cohen: A coefficient of agreement for nominal scales. In:Educational and Psychological Measurement. 20, 1960, 37-46.
- J. Cohen: Weighted kappa: Nominal scale agreement with provision for scaled disagreement or partial credit. In: Psychological Bulletin. 1968, 213-220.
- J. Cohen: Weighted chi square: An extension of the kappa method. In: Education and Psychological Measurement. 32, 1972, 61-74.
- J. L. Fleiss: The measurement of interrater agreement. In: ders., Statistical methods for rates and proportions. 2. Auflage. John Wiley & Sons, New York 1981, S. 212-236, Kapitel 13.
- J. L. Fleiss, J. Cohen: The equivalence of weighted kappa and the intraclass correlation coefficient as measures of reliability. In: Educational and Psychological Measurement. 33, 1973, 613-619.
- W. Greve, D. Wentura: Wissenschaftliche Beobachtung: Eine Einführung. PVU/Beltz, Weinheim 1997.
- J. R. Landis, G. G. Koch: The measurement of observer agreement for categorical data. In: Biometrics. 33, 1977, 159–174.
- W. A. Scott: Reliability of content analysis: The case nominal scale coding. In: Public Opinion Quarterly. 19, 1955, 321-325.
- A. von Eye: An Alternative to Cohen's κ. In: European Psychologist. 11, 2006, 12-24.
Weblinks
- Kappa-Maße im Überblick (französ. Website)
Wikimedia Foundation.