- Datenschürfung
-
Unter Data Mining (englisch für „Datenschürfen“) versteht man die systematische Anwendung von Methoden, die meist statistisch-mathematisch begründet sind, auf einen Datenbestand mit dem Ziel der Mustererkennung. Hierbei geht es vor allem um das Durchsuchen sehr großer Datenbestände, weswegen vor allem solche Methoden betrachtet werden, die eine hervorragende asymptotische Laufzeit haben. Bei Verzicht auf Modellannahmen über den Datenentstehungsprozess ergeben sich auch bei kleinen oder mittleren Datenbeständen sinnvolle Anwendungsmöglichkeiten. In der Praxis, vor allem im deutschen Sprachgebrauch, etablierte sich der angelsächsische Begriff "Data Mining" für den gesamten Prozess der so genannten "Knowledge Discovery in Databases".
Inhaltsverzeichnis
- 1 Allgemeines
- 2 Definition
- 3 Problemtypen des Data-Mining
- 4 Methodologie des Data-Mining-Prozesses
- 5 Technik
- 6 Anwendungsgebiete
- 7 Literatur
- 8 Weblinks
Allgemeines
Große Datenmengen entstehen heute in Unternehmen, Forschungsprojekten, Verwaltungen oder im Internet. Data-Mining ermöglicht das automatische Auswerten solcher Datenbestände mit Hilfe statistischer Verfahren, künstlicher neuronaler Netze, Fuzzy-Clustering-Verfahren oder genetischer Algorithmen. Ziel dabei ist das Aufspüren von Regeln und Mustern bzw. statistischen Auffälligkeiten. So lassen sich z. B. Änderungen im Verhalten von Kunden oder Kundengruppen aufspüren und Geschäftsstrategien können darauf ausgerichtet werden. Es kann aber auch abweichendes Verhalten einzelner Personen erkannt werden. Dies ruft Datenschützer auf den Plan, welche die Anwendung der Verfahren des Data-Mining kritisch begleiten.
Definition
Bensberg versteht Data-Mining als integrierten Prozess, „der durch Anwendung von Methoden auf einen Datenbestand Muster entdeckt“. Der Begriff Data-Mining wird hier aus prozessorientierter Sicht definiert; Ziel ist die Erkennung von Mustern. Bewusst wird in dieser Definition auf den Begriff der Information verzichtet, da Data-Mining der sigmatischen Ebene der Semiotik zugeordnet wird.
Bensberg verzichtet auf die vielfach in der Literatur zu findende Beschränkung auf große Datenmengen: Auch kleinere Datenmengen können bedeutungsvolle Muster enthalten, die sich durch Data-Mining entdecken und aufzeigen lassen. Eine Abgrenzung von Data-Mining zur statistischen Datenanalyse sowie eine Beschränkung der dem Data-Mining zuordenbaren Methoden findet jedoch nicht statt (Lit.: Bensberg, S. 64).
Im Folgenden wird Data-Mining in Anlehnung an Bensberg als integrierter Prozess verstanden, der durch Anwendung von Data-Mining-Techniken auf einen Datenbestand Muster entdeckt und kommuniziert. Data-Mining-Techniken sind Techniken, die der explorativen Datenanalyse zugeordnet werden können. Ziel der explorativen Datenanalyse – und damit konstruierendes Merkmal für die Definition von Data-Mining-Techniken – ist über die Darstellung der Daten hinaus die „Suche nach Strukturen und Besonderheiten [...]. Sie wird daher typischerweise eingesetzt, wenn die Fragestellung nicht genau definiert ist oder auch die Wahl eines geeigneten statistischen Modells unklar ist.“
Der Data-Mining-Prozess umfasst somit, ausgehend von der Datenselektion, alle Aktivitäten, die zur Kommunikation von in Datenbeständen entdeckten Mustern notwendig sind. HUKEMANN unterteilt diesen Prozess in Anlehnung an FAYYAD, PIATETSKY-SHAPIRO und SMYTH in die Phasen: Aufgabendefinition, Selektion und Extraktion, Vorbereitung und Transformation, Mustererkennung, Evaluation und Präsentation.
Da der Data-Mining-Prozess auf der sigmatischen Ebene stattfindet, stellt sich die Frage, inwieweit die Evaluation der Ergebnisse als Bestandteil des Data-Mining-Prozesses gelten kann. Während in der Phase der Mustererkennung die prädiktive und deskriptive Genauigkeit geprüft wird, werden entdeckte Muster im Rahmen der Evaluation auf ihre Relevanz, ihre Verständlichkeit, ihre Nützlichkeit und Verwertbarkeit sowie auf ihre Neuheit geprüft. Die hierbei zugrunde liegenden Gütefunktionen sind stark abhängig von subjektiven Einflussfaktoren und damit der pragmatischen Ebene zuzugliedern.
Die Annahme, dass für eine beliebige Fragestellung und die daraus abgeleiteten Aufgabendefinition der Data-Mining-Prozess erfolgreich verläuft, ist nicht haltbar. In der Praxis scheitert dieser Prozess regelmäßig sowohl an fehlenden wie auch an fehlerhaften Datenquellen und ist unter Umständen schon deshalb unbefriedigend, weil die Datenbank in vielen Fällen täglich erweitert wird. So verweisen Hippner und Wilde darauf, dass die einzelnen Phasen in „intensiver Interaktion mit dem Anwender und mit zahlreichen Rückkopplungen ablaufen“. Berry und Linoff verzichten vollständig auf die Einbettung der Aufgabendefinition in den Data-Mining-Prozess. So bleibt gewährleistet, dass auch die ungerichtete Suche nach Mustern, der keine zentrale Fragestellung vorangeht, durch den Data-Mining-Prozess abgebildet werden kann. Zur Gewährleistung von Effektivität und Effizienz muss jedoch umfassendes Wissen über Aufgabenstellung und Domänenbezug beim Anwender vorhanden sein. Nur so ist sichergestellt, dass alle Möglichkeiten und Chancen, welche die domänenspezifische Fragestellung bietet, genutzt werden und etwaige Probleme im Hinblick auf das Gesamtziel betriebswirtschaftlich sinnvoll gelöst werden.
Im Folgenden wird der Data-Mining-Prozess in vier Phasen unterteilt: Datenselektion, Datenvorbereitung, Mustererkennung und Kommunikation.
Problemtypen des Data-Mining
Einen pragmatischen, in der einschlägigen Literatur einheitlich anerkannten Ordnungsrahmen zur Systematisierung der verschiedenen Problemtypen liefern Fayyad, Pietetsky-Shapiro und Smyth. Dabei werden diese den Oberklassen Beschreibungsprobleme und Prognoseprobleme zugeordnet. Im Folgenden werden die verschiedenen Problemtypen im Rahmen des situativen Kontextes vorgestellt.
Beschreibungsprobleme
Unter Beschreibungsproblemen wird die Gruppe von Problemtypen zusammengefasst, deren Ziel in der Beschreibung der kausalen Zusammenhänge des Datengenerierungsprozesses liegt. Die Qualität eines entdeckten Musters kann anhand von methodenspezifischen Qualitätskriterien bestimmt werden, die die deskriptive Akkuratheit des Musters bewerten.
Beschreibung
„Die Zielsetzung der Datenbeschreibung ist die Zusammenfassung der wesentlichen Charakteristika der Daten in möglichst kompakter Form.“ Hippner und Wilde zählen die Deskription nicht zum Kern des Data-Mining. Berry und Linoff führen jedoch an, dass leicht verständliche Beschreibungen oftmals auch Erklärungen suggerieren, die dann unser Verständnis für den Datenentstehungsprozess verbessern. Zwar lassen sich deskriptive Verfahren nicht der explorativen Datenanalyse zuordnen, jedoch erfüllen verschiedene deskriptive Methoden ebenfalls die Ziele des Data Mining. Sie helfen, Fragestellungen zu präzisieren, wenn diese nicht genau definiert sind, und unterstützen den Anwender bei der Suche nach Strukturen und Besonderheiten. Deskriptive Verfahren sind aufgrund der genannten Eigenschaften dem Data-Mining zuzuordnen. Als modernes, deskriptives Verfahren ist OLAP zu nennen, das durch verschiedene Navigationstechniken die gerichtete wie die ungerichtete Suche in den Daten erleichtert.
Abweichungsanalyse
Im Rahmen der Abweichungsanalyse werden solche Informationsobjekte ermittelt und analysiert, die für bestimmte Merkmalswerte von einer Norm oder einem erwarteten Wert abweichen. Das Ziel besteht darin, diese Abweichungen zu analysieren und zu interpretieren. Diese können auf die Verschiebung alter oder die Entwicklung neuer Muster im zugrunde liegenden Datengenerierungsprozess hindeuten und dadurch Anlass geben, existierende Erklärungsmodelle bezüglich ihrer Gültigkeit zu hinterfragen.
Abhängigkeitsanalyse
Das Ziel von Abhängigkeitsanalysen ist die Entdeckung von signifikanten Dependenzen zwischen den Attributen eines Informationsobjektes. Dabei unterscheidet man bei der Abhängigkeitsanalyse, ob die Zieldaten und die Richtung der Kausalitätsbeziehung zwischen den Attributen bekannt sind oder nicht. Sind sie bekannt, können Regressionsverfahren, Bayes’sche Netze oder Entscheidungsbäume eingesetzt werden, um sie zu konkretisieren. Klassische Verfahren, die derartiges Wissen nicht voraussetzen, sind die Assoziationsanalyse oder die Korrelationsanalyse. Sequenzanalysen wiederum ermitteln Abhängigkeiten aus der zeitlichen Entwicklung von Informationsobjekten.
Der wohl klassischste Vertreter dieser Problemgruppe ist die sogenannte Warenkorbanalyse, bei der Informationen über das gleichzeitige Interesse der Akteure für mehrere Leistungen oder Leistungsgruppen analysiert und in wirtschaftliches Verhalten umgesetzt werden. Dabei wird bei der klassischen Assoziationsanalyse, ausgehend von nachgefragten Leistungsbündeln, auf die Komplementarität dieser Leistungen geschlossen.
Gruppenbildung (Clustering)
Die Gruppenbildung „zielt auf die Aufspaltung der Daten in interessante und sinnvolle Teilmengen oder Klassen.“ Dabei ist die Zielvorstellung, dass Objekte innerhalb einer Klasse möglichst homogen, Objekte aus unterschiedlichen Klassen möglichst heterogen zueinander sind. Die Quantifizierung des Homogenitätsgrades geschieht über ein Proximitätsmaß, das hinsichtlich des Skalenniveaus und der Variablenstruktur ausgewählt werden muss. Die statistischen Segmentierungsverfahren lassen sich in vier Gruppen unterteilen: Während deterministische Verfahren (Nearest-Neigbourhood-Verfahren, k-means-Verfahren) die eindeutige Zuordnung von Informationsobjekten zu Clustern verlangen, arbeiten probabilistische Verfahren mit Zugehörigkeitsgraden, deren Summe sich für jedes Element auf Eins summiert. Possibilistische Verfahren (Fuzzy-Cluster-Verfahren) heben diese Restriktion auf, so dass Elemente auch mehreren Klassen zugeordnet oder auch gar keiner Klasse zugeordnet werden können. Unvollständige Segmentierungsverfahren (Multidimensionale Skalierung) erzeugen eine räumliche Darstellung der Objekte, ohne eine Gruppeneinteilung vorzunehmen. Neben den statistischen Verfahren können zur Gruppenbildung auch Verfahren des maschinellen Lernens eingesetzt werden, beispielsweise Künstliche Neuronale Netze.
Die Gruppenbildung wird im Allgemeinen aus zwei Gründen durchgeführt: Bezogen auf die (potenziellen) Nachfrager versucht insbesondere die Clusteranalyse, die typischen Charakteristika von Gruppen zu identifizieren, um daraus gruppenspezifische Leistungen (von individuellen Kommunikationswegen über individuelle Kommunikationsinhalte bis hin zu individuellen Leistungsversprechen) zu entwickeln. Bezogen auf die Menge der im relevanten Markt angebotenen Leistungsversprechen versuchen insbesondere die Ansätze der multidimensionalen Skalierung, Nischen zu entdecken, um diese durch neuartige Angebote zu bedienen.
Prognoseprobleme
Das Ziel von Prognoseproblemen ist die Entwicklung von mathematischen Modellen, mit deren Hilfe aus einem gegebenen Input der zu erwartende Output bestimmt werden kann. Die Qualität eines solchen Modells kann über seine Prognosefähigkeit, also über seine prädiktive Akkuratheit, bestimmt werden.
Klassifikation
Klassifikationsverfahren konstruieren Modelle, mittels deren Informationsobjekte anhand von objekt- und umweltspezifischen Eigenschaften vordefinierten Klassen zugeteilt werden können. Durch diese Zuordnung kann das Objekt mit den klassenspezifischen Eigenschaften in Verbindung gebracht werden, um so das erwartete Verhalten eines Informationsobjektes abzuleiten. Zum Aufstellen eines mathematischen Modells werden dazu eine feste Anzahl an Klassen sowie Beispiele von Klasseninstanzen und deren Attributwerte benötigt. Mathematische Methoden, die für das Aufstellen von Klassifikationsmodellen hilfreich sind, entstammen sowohl der klassischen Statistik (Diskriminanzanalyse, K-Nächste-Nachbarn-Methode) als auch dem maschinellen Lernen. Symbolische Lernverfahren, beispielsweise Entscheidungsbaumverfahren oder Regelinduktion, stellen Verfahren dar, welche für den Anwender verständliche Klassenbeschreibungen generieren. Subsymbolische Verfahren wie Künstliche Neuronale Netze arbeiten hingegen nach dem Black-Box-Prinzip, Klassenbeschreibungen sind nicht aus dem konstruierten Modell heraus ableitbar.
Wirkungsprognose
Das Ziel der Wirkungsprognose ist es, ähnlich wie bei der Klassifikation, Zielwerte zu bestimmen. Anders als bei der Klassifikation sind diese Zielwerte jedoch quantitativer Natur. Die Regressionsanalyse ist die typische Vertreterin der klassischen statistischen Verfahren zur Formalisierung von Wirkungszusammenhängen. Diese Methode ist beschränkt auf lineare Zusammenhänge, so dass für unbekannte Zusammenhänge oftmals Künstliche Neuronale Netze, Box-Jenkins-Verfahren oder regelbasierte Verfahren eingesetzt werden.
Mittels Klassifikationsverfahren und Wirkungsprognosen können Systeme konstruiert werden, die für die flexiblen Gestaltungsparameter als Input den erwarteten Output einer Zielgröße bestimmen. Durch den Einsatz von Entscheidungsbäumen oder künstlichen neuronalen Netzen können diese Gestaltungsparameter unter gegebenen Umweltbedingungen optimiert werden.
Methodologie des Data-Mining-Prozesses
Datenselektion und -extraktion
Die Selektion erfolgt in zwei Schritten: „Im Rahmen der vertikalen Datenselektion werden die relevanten Analyseobjekte (Datensätze, Tupel) bestimmt. Die relevanten Attribute werden im Zuge der horizontalen Datenselektion festgelegt.“ Ist der „richtige“ Aggregationsgrad der Daten in dieser Phase noch unbekannt, sollte der niedrigste verfügbare Wert ausgewählt werden. Anschließend werden die Daten aus den Systemen extrahiert. Verfügbare Metadaten sollten für die Auflösung semantischer Unklarheiten während der Datenbereinigung und während der Ergebnisinterpretation ebenfalls extrahiert werden.
Die Qualität und Quantität der ermittelten Daten beeinflusst dabei maßgeblich die späteren Analysemöglichkeiten sowie die Qualität des Ergebnisses. Domänenspezifisches Wissen über potenzielle Datenquellen und ihre Erschließung ist daher unabdingbar. Rechtliche Restriktionen (insbesondere zum Datenschutz) müssen dabei jedoch berücksichtigt werden. Nachdem die Daten erfolgreich aus den jeweiligen Systemen extrahiert worden sind, müssen sie für die weitergehende Analyse inhaltlich und formal aufbereitet werden.
Die ideale Anwendungsumgebung stellt alle benötigten Daten konsistent abgebildet in einem Data Warehouse bereit. In der Praxis ist dies jedoch regelmäßig nicht der Fall. Relevante Daten liegen meist zerstreut in den Datenbanken der historisch gewachsenen operativen Systeme. Benötigte Daten werden teilweise gar nicht oder nur unzureichend durch diese Systeme aufgezeichnet, wenn aus operativer Sicht keine Notwendigkeit für eine Erfassung ersichtlich ist. Grundsätzlich sollten neben den verschiedenen Datenbanken der operativen Systeme daher auch folgende Datenquellen auf ihre Relevanz geprüft werden:
Daten in Papierform
Ist zum Zeitpunkt der Erhebung kein unmittelbarer Nutzungsbedarf erkennbar, wird auf eine maschinelle Erfassung von Daten oftmals verzichtet, so beispielsweise bei Laufzetteln. Daten in Papierform, die häufig bereits in semistrukturierter Form vorliegen und damit leicht in eine digitale Form transformiert werden können, stellen eine wichtige potenzielle Informationsquelle dar.
Nichtformatierte Daten
Data-Mining-Methoden setzen auf formatierten Daten in Form von nominal, ordinal oder kardinal skalierten Merkmalen auf. Nichtformatierte Daten, beispielsweise Freitextdokumente (Kundenbeschwerden, Anfragen etc.), werden bei der Datenselektion meist pauschal ausgelassen. Allein über deskriptive Verfahren lassen sich hieraus bereits relevante Daten ermitteln. Die Anwendung verschiedener Textmining-Techniken ermöglicht die tiefergehende Analyse von unstrukturierten Daten in Textform.
Implizites Wissen
Mit Methoden des Wissensmanagements kann implizites Wissen, das nicht formal dokumentierbar ist, explizit und formatiert abgebildet werden.
Externe Datenquellen
Auch externe Datenquellen sollten bei der Datenselektion auf ihre Relevanz geprüft werden. Neben den – meist kommerziellen – Brancheninformationsdiensten stellt das Internet eine wichtige externe Datenquelle dar.
Datenaufbereitung
Die Datenaufbereitung stellt eine elementare Aufgabe des Data-Mining dar. Dies unterstreicht CABENA, wenn er feststellt, dass lediglich zehn Prozent des Zeitaufwandes im Data-Mining unmittelbar auf den Einsatz von Data-Mining-Methoden entfallen, während 90 Prozent in die Datenaufbereitung und Ergebnisnachbearbeitung fließen. Empirische Untersuchungen belegen Fehlerwahrscheinlichkeiten in den Rohdaten von bis zu 30 Prozent und damit auch die Relevanz der Datenbereinigung.
Datenbereinigung
Ziel dieses Schrittes ist auch die Struktur- und Formatvereinheitlichung zur Steigerung der Datenqualität. Erst wenn eine ausreichende Datenqualität sichergestellt ist, können die Daten für die weitere Analyse transformiert und codiert werden. Insbesondere bei heterogenen Datenquellen tauchen bei der Integration der Daten erhebliche Probleme auf:
Inkompatible Identifikationsschlüssel
In einer zusätzlichen Relation müssen inkompatible Identifikationsschlüssel einander zugeordnet werden. Dies kann über einen Abgleich der Identifikationsdaten geschehen – jedoch ist dieses Verfahren fehleranfällig. Ein effizienteres Verfahren stellt der Einsatz so genannter Matchcodes dar. Dieser künstliche Primärschlüssel (auch Surrogate Key genannt), der anhand von wenig fehleranfälligen Zeichenfolgen aus verschiedenen Attributen gebildet wird, liefert im Allgemeinen bessere Ergebnisse und ermöglicht zugleich das Erkennen und Löschen von Doubletten.
Semantische Abbildungsdefekte
Ohne Metadaten oder entsprechendes Domänenwissen zur Datenbasis können semantische Probleme nicht aufgelöst werden. Semantische Probleme manifestieren sich „in Form von Synonymen (unterschiedliche Bezeichnung des gleichen Dateninhaltes in verschiedenen Datenquellen) und Homonymen (gleiche Bezeichnung unterschiedlicher Dateninhalte, beispielsweise wird das Merkmal „inaktiver Kunde“ in zwei Datenquellen sechs bzw. 18 Monate nach dem letzten Kauf vergeben)“. Allgemeingültige Verfahren zur Lösung solcher Probleme gibt es nicht, vielmehr muss mit Hilfe von Metadaten sowie von domänenspezifischem Wissen über die Daten versucht werden, semantische Probleme individuell zu lösen.
Syntaktische Abbildungsdefekte
Verschiedene Schreibweisen (Weseler Straße vs. Weselerstraße, Meier vs. Maier) sowie verschiedene Repräsentationen eines identischen Sachverhalts (weiblich vs. f) führen zu syntaktischen Problemen. Durch eine Vereinheitlichung der syntaktischen Abbildung von Attributen sowie mit Hilfe von Nachschlagewerken (Straßenverzeichnissen etc.) können solche Probleme gelöst werden.
Zeitlogische Abbildungsdefekte
Liegt zwischen der letzten Aktualisierung eines Datensatzes und dem Tag der Datenselektion ein für die jeweilige Attributsausprägung relativ langer Zeitraum steigt die Wahrscheinlichkeit, dass sich dieser geändert haben wird. Die richtig erhobenen Werte unterliegen einem zeitlogischen Abbildungsdefekt, der oftmals nur schwer aufgelöst werden kann. Liefert auch eine Rückkopplung zur Datenselektion keine sicheren Werte, ist im Einzelfall zu prüfen, ob kritische Werte als Fehlwerte behandelt werden müssen.
Redundanzen
Ursache für Redundanzen sind im Allgemeinen entweder fehlende Namenskonventionen oder eine fehlende Normalisierung der zugrunde liegenden Datenmodelle. Durch den Verzicht auf einheitliche Namenskonventionen, die sich über alle operativen Systeme erstrecken, kann ein Attribut in verschiedenen Quellen unter verschiedenen Attributsbezeichnungen gespeichert werden und nach der Zusammenführung der Daten doppelt auftreten. Bei einer fehlenden Normalisierung des Datenmodells können funktionale Abhängigkeiten zwischen verschiedenen Attributen auftreten, die ebenfalls redundante Informationen repräsentieren. Werden diese Redundanzen nicht erkannt und gegebenenfalls eliminiert, können sie fälschlicherweise als triviale Muster im Ergebnis auftauchen.
Fehlwerte
„In relationalen Datenbanken taucht das Problem fehlender Werte (missing values) häufig auf, da oftmals dieselbe Satzlänge für jeden Datensatz auch dann gefordert ist, wenn für einige Felder keine Eintragungen möglich sind“ oder aus Sicht des eintragenden Mitarbeiters für die aktuelle Transaktion unwichtig erscheinen. Dabei ist zu unterscheiden zwischen echten Fehlwerten, deren Daten nicht bestimmbar sind, und unechten Fehlwerten, deren Daten nicht bestimmt wurden. Die Attributsausprägungen von unechten Fehlwerten können durch eine Rückkopplung zur ersten Phase des Data-Mining-Prozesses, der Datenselektion und -extraktion, teilweise ermittelt werden. Das Korrigieren der Fehlwerte nach gängigen Ersetzungsstrategien ist jedoch nur unter Vorbehalt durchzuführen und auch das Löschen der betroffenen Datensätze kann, im Falle systematischer Fehler, zu einer Verschiebung der Ergebnisse führen. Bei der Behandlung von Fehlwerten ist zu beachten, dass das Fehlen von Werten auch eine wertvolle Information darstellen kann. Interessante Ergebnisse können sich hier insbesondere dann ergeben, wenn das Fehlen einer Angabe direkt mit ihrer Ausprägung zusammenhängt. In jedem Fall verfolgt die Behandlung von Fehlwerten das Ziel, ein „Höchstmaß an Informationsgehalt aus der vorhandenen Datenbasis zu ziehen, ohne ein tolerierbares Mass an Verzerrung zu überschreiten.“
Falschwerte
Attributsausprägungen, die objektiv falsch sind (wie z. B. ein Geburtsdatum in der Zukunft), müssen überarbeitet werden. Lassen sich dabei die richtigen Werte nicht ermitteln, so ist der Falschwert zu löschen und als Fehlwert zu behandeln. Dabei lassen sich Falschwerte in zwei Gruppen unterteilen: Echte Falschwerte entstehen, wenn zum Abschluss einer Transaktion erforderliche Daten fehlen oder wenn ein Bedürfnis vorhanden ist, die Daten nicht preiszugegeben – Mitarbeiter oder auch Kunden neigen in solchen Fällen dazu, fiktive Werte anzugeben. Unechte Falschwerte wurden zwar erhoben, der im System gespeicherte Wert entspricht aber nicht dem tatsächlich genannten. Zu einer dieser beiden Gruppen zählen oftmals so genannte Ausreißer, die sich durch signifikante Distanzen zu den übrigen Werten auszeichnen. Dabei können neben mathematischen Verfahren auch Visualisierungstechniken eingesetzt werden, um Ausreißer zu ermitteln. Es ist jedoch im Einzelfall zu prüfen, ob diese Werte entgegen der ersten Vermutung nicht doch korrekt erfasst wurden und damit einen wichtigen, da atypischen, Sachverhalt repräsentieren. Ziel der Datenaufbereitung ist es, die Datenqualität zu steigern. Jedoch wird eine fehlerfreie Datengrundlage trotz intensiver Bemühungen selten zu erreichen sein. Schwächen im Pflegestand der Daten stehen einer erfolgreichen Datenanalyse grundsätzlich nicht im Wege, sollten jedoch bei der Interpretation der Ergebnisse berücksichtigt werden. Sobald eine ausreichende Datenqualität sichergestellt ist, müssen die Daten durch verschiedene Transformationen für die spätere Verwendung vorbereitet werden.
Aggregation von Merkmalen
Verschiedene Gründe zwingen zu einer Aggregation der Daten entlang bekannter hierarchischer Strukturen. Nicht aggregierte Daten führen insbesondere bei Assoziationsanalysen auf Datenbeständen mit einer Vielzahl von Attributen, wie etwa bei der Warenkorbanalyse für ein breites Sortiment, unweigerlich zu Performanzproblemen. Dann ist es unumgänglich, in der Hierarchieebene so lange aufwärts zu wandern, bis diese Performanzprobleme nicht mehr auftauchen. Die Auswahl des hierarchischen Pfades, entlang dem die Aggregation der Daten erfolgt, ist dabei abhängig von den verfolgten Zielen und muss im Einzelfall bestimmt werden. Zeigt sich, dass im vorliegenden Aggregationsgrad bestimmte Attributausprägungen selten auftauchen, kann dies zu Lasten der Signifikanz des Ergebnisses gehen: Zu dünn besetzte Datentabellen stellen für die weitere Analyse keine tragfähige Basis dar. Auch in solchen Fällen ist es unabdingbar, die Daten zu aggregieren. Bei der Wahl der Aggregationsebene ist zu bedenken, dass eine Aggregation die beobachtbare Streuung des jeweiligen Merkmals reduziert, „mit der Folge, dass sich Qualitätsmaße für Data-Mining-Modelle, die auf den erklärten Varianzanteil eines Zielmerkmals abstellen, mit wachsender Aggregation systematisch verbessern“. Daten können ebenfalls dann aggregiert werden, wenn sie im aktuellen Aggregationsniveau Informationen enthalten, die nicht von Interesse sind. In diesem Fall ist die Aggregation der Daten jedoch formal der Phase der Datenselektion zuzuordnen. Oder auch nicht.
Berechnung neuer Attribute
„Bei der Transformation der Daten können noch neue, für die Analyse als sinnvoll erscheinende Attribute wie Summen, Abweichungs- und Durchschnittswerte definiert oder inhaltlich abhängige Felder zusammengefasst werden.“ So können Attribute geschaffen werden, die die Komplexität senken und damit die Interpretationsfähigkeit der generierten Lösung erhöhen. Der Informationsverlust einer Summierung (oder auch Mittelwertbildung) kann durch die gleichzeitige Ermittlung von Varianz und Schiefe annähernd ausgeglichen werden. Die Berechnung von Verhältniskennzahlen ist für solche Attribute ratsam, für die die Datenbasis eine stark heterogene Grundgesamtheit repräsentiert. So können beispielsweise Kundenumsätze von Firmenkunden zum Zwecke der Vergleichbarkeit in ein Verhältnis zur Mitarbeiterzahl der jeweiligen Firma gesetzt werden. Domänenspezifisches Wissen ist unumgänglich, um Verhältniskennzahlen zu bestimmen, die der Heterogenität der Datenbasis gerecht werden. Eine sinnvoll bestimmte Verhältniskennzahl bietet dabei – mehr als die Attribute für sich – eine Chance, interessante Ergebnisse zu generieren. Fundiertes A-priori-Wissen über kausale Zusammenhänge zwischen den Attributen ist die Voraussetzung, um durch mathematische Transformation einzelner Attribute die Komplexität der später einzusetzenden Methode reduzieren zu können. So können nichtlineare Wirkungszusammenhänge in lineare Wirkungsrelationen transformiert und dann mit weniger komplexen Data-Mining-Modellen erforscht werden. Zeitreihen können durch Mittelwertbildung, aber auch durch lineare Transformation – mit unterschiedlicher Gewichtung der einzelnen Werte – zu einer Kennzahl zusammengefasst werden. Auch kann die Verdichtung von Zeitreihen mittels polynomischer Funktionen erfolgen, durch die sich beliebige mathematische Funktionen approximieren lassen.
Umgang mit stark korrelierten Attributen
Neben der Selektion redundanter Attribute führt auch die Berechnung neuer Attribute zu Abhängigkeiten, die das Ergebnis durch eine Vielzahl trivialer Erkenntnisse aufblähen. Zugleich wirken sie sich negativ auf die Performanz der Analyse aus. Hier setzt die Reduktion von Attributausprägungen an. Die manuelle Vorauswahl von Attributen aufgrund domänenspezifischem A-priori-Wissen ist formal der Phase der Datenselektion zuzuordnen. Die Hauptkomponenten- oder Faktorenanalyse ermöglicht eine maximale Reduzierung der Dimensionalität bei minimalem Informationsverlust. Dabei werden ausgehend von den vorhandenen Attributen neue, synthetische Merkmale generiert, die maximal unkorreliert sind. Den daraus resultierenden Vorteilen steht eine erschwerte Interpretation der Ergebnisse gegenüber. Insbesondere für methodisch unerfahrene Nutzer sind die Ergebnisse unanschaulich und schwer analysierbar, da ein direkter Zusammenhang zwischen Ergebnis und Datenbasis scheinbar nicht vorhanden ist. Besteht a priori der Verdacht auf Korrelation verschiedener Merkmale und ist die Hauptkomponentenanalyse wegen der genannten Probleme nicht zielführend einsetzbar, stehen verschiedene Data-Mining-Methoden zur Verfügung, die automatisiert aussichtsreiche Gruppen von Erklärungs- oder Beschreibungsmerkmalen selektieren. Sollte in der späteren Phase der Mustererkennung erkannt werden, dass verschiedene Attribute hoch korreliert sind und die Berücksichtigung dieser Attribute keinen Zugewinn an Informationen darstellt, kann eine Rückkopplung zu dieser Phase des Prozesses stattfinden. Es wird dann das typischste, aussagekräftigste oder anschaulichste Attribut ausgewählt, während die anderen eliminiert werden.
Datenkodierung
Das Ziel der Datencodierung ist die inhaltliche Vorbereitung der selektierten und aufbereiteten Daten. Dafür stehen verschiedene Methoden zur Verfügung, die im Folgenden erläutert werden.
Normierung
Die Normierung von Werten ist ein Prozess, bei dem der Wertebereich eines Attributes mit Hilfe einer Normierungsfunktion zielführend verändert wird. Eine zielführende Veränderung des Wertebereichs für ein einzelnes Merkmal leitet sich im Allgemeinen aus den methodischen Anforderungen der eingesetzten Data-Mining-Methoden ab. Die Normierung mehrerer Attribute auf einen einheitlichen Wertebereich ist zielführend, wenn eine Vergleichbarkeit (bei Gleichgewichtung der verschiedenen Attribute) zwischen ihnen hergestellt werden soll. Als Beispiel für Normierungsfunktionen sei die z-Transformation genannt, die durch Mittelwertsubtraktion und Division durch die Standardabweichung den Mittelwert auf null und die Varianz auf Eins normiert:
Erfordert die Auswahl der eingesetzten Data-Mining-Methoden eine Normierung auf das Intervall [0,1], so kann ein Merkmal durch die dezimale Skalierung (Division durch die kleinste Zehnerpotenz, die sicherstellt, dass die Absolutwerte aller Merkmale kleiner 1 sind) auf das gewünschte Intervall abgebildet werden:
Normierungsfunktionen lassen sich nur für quantitative Merkmale aufstellen und sind eindeutig umkehrbar.
Skalentransformation
In der Statistik unterscheidet man zwischen vier Skalenarten für Merkmale: der Nominal-, der Ordinal-, der Intervall- und der Verhältnisskala, wobei die beiden letztgenannten Skalen oft zur so genannten Kardinalskala zusammengefasst werden. Das Ziel der Skalentransformation besteht darin, ein Merkmal von einer Skala in eine andere zu überführen. Dabei treten bei der Umwandlung von kardinalskalierten Merkmalen in ordinal- oder nominalskalierte Merkmale selten Probleme auf – lediglich eine geeignete Bewertungsfunktion muss hierfür definiert werden. Verschiedene Data-Mining-Verfahren verlangen jedoch quantitative Inputdaten, so dass qualitative Daten gegebenenfalls in quantitative Daten umgewandelt werden müssen. Jedoch sollten diese Verfahren mit äußerster Vorsicht betrachtet werden. Häufig hat man dann keinen sinnvollen Output mehr. Sinnvoller ist es direkt die Daten innerhalb der Methoden richtig zu behandeln, anstatt willkürliche Verfahren zu verwenden, die häufig ohne statistische Grundlage sind.
Diese Umwandlung leisten verschiedene Codierungstechniken: So ist für nominalskalierte Daten beispielsweise die „one of n“-Codierung, auch bekannt als flattening, einsetzbar, während für ordinalskalierte Daten die „fuzzy one of n“-Codierung, die „gradient one of n“-Codierung bzw. die „thermometer“-Codierung genutzt werden können.
Strukturelle Transformation
Ziel des abschließenden Teils der Datenaufbereitung ist es, die Daten strukturell auf die Analyse vorzubereiten, so dass sie „in einem Format vorliegen, das von den in der nächsten Phase anzuwendenden Werkzeugen zur Mustererkennung verarbeitet werden kann“. Das Ergebnis dieses Schrittes ist der fertig aufbereitete Zieldatenbestand, der in einem – für die jeweils anzuwendende Methode passenden – Format vorliegt.
BERRY und LINOFF schlagen darauf aufbauend eine Dreiteilung der Datengrundlage in einen Trainingsdatensatz, einen Testdatensatz und einen Evaluierungsdatensatz vor. Die Gruppeneinteilung erfolgt standardmäßig durch eine (quasi-)zufällige Zuordnung der Datensätze zu den drei Gruppen. WEISS schlägt jedoch für die Prüfung der prädiktiven Akkuratheit von Zeitreihenanalysen eine besondere Berücksichtigung von aktuellen Daten im Evaluationsdatensatz vor, mit dem Ziel, die Aussagekraft des Systems für aktuelle Problemstellungen zu prüfen.
Mustererkennung
Der Prozess der Mustererkennung lässt sich formal in drei Phasen unterteilen: die Modellspezifikation, die Modellevaluation und die Suche. „Im Rahmen der Modellspezifikation findet die Auswahl des Analyseverfahrens [...] statt.“ „Dazu ist es erforderlich, aus der Fülle von Data-Mining-Methoden diejenige(n) herauszufiltern, die zur Bearbeitung des vorliegenden Problemtyps geeignet sind.“ Anschließend müssen diese Methoden unter Berücksichtigung der Aufgabendefinition und der Besonderheiten des Datenbestandes für das jeweilige Problem instanziiert werden. Dabei ist jedoch zu berücksichtigen, dass die Attraktivität eines komplexen Modells trotz niedriger Varianz gering ist, da sowohl die Prognosefähigkeit als auch die Verständlichkeit des Modells mit steigender Komplexität sinkt. Das Modell bildet zudem mit steigender Komplexität zunehmend datensatzspezifische Artefakte ab, welche die Generalisierungsfähigkeit des Modells in Frage stellen. „Je stärker man sich allerdings bei der Auswahl von Data-Mining-Methoden hinsichtlich der Modellkomplexität [...] beschränkt, desto größer wird die Gefahr, dass die verbleibenden Freiheitsgrade für eine zutreffende Beschreibung des Datengenerierungsprozesses nicht mehr ausreichen.“ Die optimale Modellkomplexität ist daher für jeden Einzelfall unter Berücksichtigung der individuellen Anforderungen an das Ergebnis zu bestimmen.
„Die Modellevaluation überprüft, in welchem Ausmaß ein entdecktes Muster bestimmte Anforderungskriterien erfüllt.“ Dabei lässt sich die Menge der Qualitätsfunktionen, die zur Überprüfung der Anforderungskriterien herangezogen werden können, in zwei Gruppen unterteilen: Für die Evaluation der deskriptiven Akkuratheit werden verschiedene verfahrensspezifische Gütekriterien herangezogen; die Evaluation der prädiktiven Akkuratheit geschieht mit Hilfe des Evaluierungsdatensatzes; geprüft wird hier die Prognosefähigkeit des Modells. Die Suche wird unterteilt in die Parametersuche und die Modellsuche. Das Ziel der Parametersuche ist die numerische Belegung der Modellparameter. Sie stellt das Ergebnis dar, das die Anwendung einer spezifischen Data-Mining-Technik auf einen bestimmten Datenbestand liefert. Die Modellsuche hingegen modifiziert im Rahmen einer iterativen Parametersuche die Modellspezifikation. Diese Suche sollte in Interaktion mit dem Benutzer geschehen, aber auch die automatisierte Traversierung des Suchraumes ist denkbar. Die Modellsuche terminiert mit den Ergebnissen der Parametersuche, wenn die im Rahmen der Modellevaluation aufgestellten Abbruchkriterien erfüllt sind.
Kommunikation
In der Phase der Kommunikation sind die entdeckten Muster in eine für den Adressaten verarbeitbare Form zu bringen und über adäquate Medien zu kommunizieren. Ist der Adressat ein Computersystem, so müssen Inhalte in einer formalen Sprache, die das Zielsystem verarbeiten kann, abgebildet werden. Für Menschen können grundsätzlich sämtliche den menschlichen Sinnesorganen zugängliche, Trägermedien genutzt werden, um Inhalte zu kommunizieren, also visuelle, akustische, gustorische, haptische und olfaktorische Medien. Bei der Auswahl des Mediums müssen individuelle Fähigkeiten und Restriktionen des Adressaten berücksichtigt werden, aber auch die Anforderungen, welche die zu kommunizierenden Inhalte an das Trägermedium stellen. Im Regelfall werden in Data-Mining-Anwendungen visuelle Medien genutzt, insbesondere Grafiken: Denn visuelle Musterpräsentationen machen komplexe Zusammenhänge für das menschliche Gehirn oftmals schneller begreifbar. FÖRSTER und ZWERNEMANN konkretisieren den Einfluss von domänenspezifischem Wissen auf die Effizienz der Darstellungsform: Textuelle Darstellungen in Form von Zusammenfassungen, Kennzahlen oder mathematischen Funktionen bieten dabei einen optimalen Support bei einem hohen domänenspezifischen Wissen, wohingegen ohne dieses Wissen die konkrete Darstellungsform eines Beispiels vorzuziehen ist. Hierbei stellt sich die Frage, welches Kommunikationsverfahren für die Übermittlung der adressatenspezifisch aufbereiteten Inhalte geeignet ist. Zurückgegriffen werden kann hier auf Push- oder Pull-Verfahren, wobei auch regelbasierte Kombinationen aus den beiden Verfahren denkbar sind.
Technik
Bei normalen Auswertungen von Datenbeständen (z. B. durch OLAP) können bestimmte, vorher festgelegte Fragestellungen bearbeitet werden. Zum Beispiel: Wie viele meiner Kunden sind zwischen 20 und 40 Jahre alt und leben in München. Beim Data-Mining werden die Datenbestände nach Regelmäßigkeiten, Mustern und Strukturen, Abweichungen und jeglicher Art von Beziehungen und gegenseitigen Beeinflussungen untersucht. Der Prozess der Mustererkennung und Wissensextraktion wird auch Knowledge Discovery in Databases genannt. Im Data-Mining, als einem kreativen Prozess, werden im Arbeitsfortschritt Hypothesen entwickelt und überprüft.
Verschiedene Data-Mining-Verfahren sind:
- Clusteranalyse: Gruppierung von Objekten aufgrund von Ähnlichkeiten
- Hauptkomponentenanalyse: Identifikation und Extraktion weniger systembestimmender Faktoren
- Faktorenanalyse: datenreduzierende Informationsverdichtung durch Bündelung mehrerer Variablen zu wenigen Faktoren
- Assoziationsanalyse: z. B. Warenkorbanalyse
- Klassifikationsverfahren: Einordnung von Objekten in bestimmte Klassen und Kategorien
- Diskriminanzanalyse: Klassifikation von Objekten unbekannter Klassenzugehörigkeit
- Entscheidungsbäume: Darstellung aufeinanderfolgender, hierarchischer Entscheidungen
- Attributsgewichtung (auch Sensitivitätsanalyse): Einfluss von Faktoren auf bestimmte Ergebnisgrößen
- Regressionsanalyse: Identifikation von Beziehungen zwischen einer abhängigen und einer oder mehrerer unabhängigen Variablen
- Support-Vector-Maschine: Aufteilung von Objekten in zwei Klassen unter Maximierung des Abstands zur Klassengrenze
- Künstliche neuronale Netze: Überführung beliebiger Eingabemuster in das gewünschte Ausgabemuster
Anwendungsgebiete
- Kundensegmentierung im Marketing (in Bezug auf ähnliches Kaufverhalten bzw. Interessen, gezielte Werbemaßnahmen)
- Warenkorbanalyse (zur Preisoptimierung, Produktplatzierung im Supermarkt)
- Management von Kundenbeziehungen (Customer Relationship Management, CRM)
- Selektion von Zielgruppen für Marketingaktionen (Kampagnenmanagement)
- Web Usage Mining (Web Mining, Personalisierung von Internetpräsenzen → Erstellung von Zugriffsprofilen)
- Text-Mining (Anwendung von Data-Mining-Verfahren auf große Mengen von (Online-)Textdokumenten)
- Player-Tracking ("optimiertes" Glücksspiel durch Spielerverfolgung bis hin zur Anpassung von Spielabläufen)
- Pharmakovigilanz (Arzneimittelüberwachung nach Marktzulassung im Hinblick auf unbekannte unerwünschte Ereignisse)
Data Mining in der aktuellen Anwendung
Literatur
- Markus Lusti: Data Warehousing and Data Mining: Eine Einführung in entscheidungsunterstützende Systeme, Springer, ISBN 3-540-42677-9
- Peter Mertens, Hans W. Wieczorrek: Data X Strategien: Data Warehouse, Data-Mining und operationale Systeme für die Praxis, Springer, ISBN 3-540-66178-6
- Thomas Pietsch, Tobias Memmler: Balanced Scorecard erstellen: Kennzahlenermittlung mit Data Mining, Schmidt, ISBN 3-503-07023-0
- Andreas Rudolph: Data Mining in action: Statistische Verfahren der Klassifikation, Shaker Verlag, ISBN 3-8265-6172-4
- Andreas Kladroba (2001): Data Warehousing und Data Mining aus Sicht des deutschen Datenschutzrechts, Marketing ZFP 23, S. 269 - 276
- Helge Petersohn: Data Mining. Verfahren, Prozesse, Anwendungsarchitektur. 2005. ISBN 978-3-486-57715-0
Weblinks
- MATLAB-Toolbox Gait-CAD (GNU General Public License)
- RapidMiner (RapidMiner: kostenlos erhältliche Open Source Data Mining Software (GNU General Public License) mit mehr als 500 verschiedenen Data Mining Methoden
- Skript "Data Mining" von Andreas Rudolph
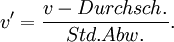
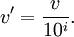
Wikimedia Foundation.