- Quicksort
-
 Eine zufällige Permutation von Integerwerten wird mit Quicksort sortiert. Die blauen Linien zeigen den Wert des rot markierten Pivotelements im jeweiligen Rekursionsschritt.
Eine zufällige Permutation von Integerwerten wird mit Quicksort sortiert. Die blauen Linien zeigen den Wert des rot markierten Pivotelements im jeweiligen Rekursionsschritt.
Quicksort (von englisch quick ‚schnell‘ und to sort ‚sortieren‘) ist ein schneller, rekursiver, nicht-stabiler Sortieralgorithmus, der nach dem Prinzip Teile und herrsche (lat. Divide et impera!, engl. Divide and conquer) arbeitet. Er wurde ca. 1960 von C. Antony R. Hoare in seiner Grundform entwickelt[1] und seitdem von vielen Forschern verbessert. Der Algorithmus hat den Vorteil, dass er über eine sehr kurze innere Schleife verfügt (was die Ausführungsgeschwindigkeit stark erhöht) und ohne zusätzlichen Speicherplatz auskommt (abgesehen von dem für die Rekursion zusätzlichen benötigten Platz auf dem Aufruf-Stack).
 Eine zufällige Permutation des Umfangs n, in der jedes Element von 1 bis n lediglich einmal vorkommt, wird mit Quicksort sortiert.
Eine zufällige Permutation des Umfangs n, in der jedes Element von 1 bis n lediglich einmal vorkommt, wird mit Quicksort sortiert.Inhaltsverzeichnis
Prinzip
Zunächst wird die zu sortierende Liste in zwei Teillisten („linke“ und „rechte“ Teilliste) getrennt. Dazu wählt Quicksort ein sogenanntes Pivotelement aus der Liste aus. Alle Elemente, die kleiner als das Pivotelement sind, kommen in die linke Teilliste, und alle, die größer sind, in die rechte Teilliste. Die Elemente, die gleich dem Pivotelement sind, können sich beliebig auf die Teillisten verteilen. Nach der Aufteilung sind die Elemente der linken Liste kleiner oder gleich den Elementen der rechten Liste.
Anschließend muss man also nur noch jede Teilliste in sich sortieren, um die Sortierung zu vollenden. Dazu wird der Quicksort-Algorithmus jeweils auf der linken und auf der rechten Teilliste ausgeführt. Jede Teilliste wird dann wieder in zwei Teillisten aufgeteilt und auf diese jeweils wieder der Quicksort-Algorithmus angewandt, und so fort. Diese Selbstaufrufe werden als Rekursion bezeichnet. Wenn eine Teilliste der Länge eins oder null auftritt, so ist diese bereits sortiert und es erfolgt der Abbruch der Rekursion, d. h. für diese Teilliste wird Quicksort nicht mehr aufgerufen.
Die Längen der Teillisten ergeben sich aus der Wahl des Pivotelements. Idealerweise wählt man das Pivot so, dass sich zwei etwa gleich lange Listen ergeben, dann arbeitet Quicksort am effizientesten. Es sollte also etwa gleich viele Elemente kleiner als das Pivot und größer als das Pivot geben.
Die Positionen der Elemente, die gleich dem Pivotelement sind, hängen vom verwendeten Teilungsalgorithmus ab. Sie können sich beliebig auf die Teillisten verteilen. Da sich die Reihenfolge von gleichwertigen Elementen zueinander ändern kann, ist Quicksort im Allgemeinen nicht stabil.
Das Verfahren muss sicherstellen, dass jede der Teillisten mindestens um eins kürzer ist als die Gesamtliste. Dann endet die Rekursion garantiert nach endlich vielen Schritten. Das kann z. B. dadurch erreicht werden, dass das ursprünglich als Pivot gewählte Element auf einen Platz zwischen den Teillisten gesetzt wird und somit zu keiner Teilliste gehört.
Allgemeine Implementierung
Pseudocode
Die Implementierung der Teilung erfolgt als In-place-Algorithmus: Die Elemente werden nicht in zusätzlichen Speicher kopiert, sondern nur innerhalb der Liste vertauscht. Dafür wird ein Verfahren verwendet, das als teilen oder auch partitionieren bezeichnet wird. Danach sind die beiden Teillisten gleich in der richtigen Position. Sobald die Teillisten in sich sortiert wurden, ist die Sortierung der Gesamtliste beendet.
Der folgende Pseudocode illustriert die Arbeitsweise des Algorithmus, wobei
datendas zu sortierende Feld ist. Dabei hat beim ersten Aufruf vonquicksort(oberste Rekursionsebene) der Parameterlinksden Wert 0 (Index des ersten Feld-Elements) undrechtsden Wertn-1(Index des letzten Feld-Elements). Die Bezeichnungenlinksundrechtsbeziehen sich auf die Anordnung des Felds:daten[0],daten[1], ... ,daten[n-1].funktion quicksort(links, rechts) falls links < rechts dann teiler := teile(links, rechts) quicksort(links, teiler-1) quicksort(teiler+1, rechts) ende endeDie folgende Implementierung der Funktion
teileteilt das Feld so, dass sich das Pivotelement an seiner endgültigen Position befindet und alle kleineren Elemente davor stehen, während alle größeren danach kommen:funktion teile(links, rechts) i := links // Starte mit j links vom Pivotelement j := rechts - 1 pivot := daten[rechts] wiederhole // Suche von links ein Element, welches größer als das Pivotelement ist wiederhole solange daten[i] ≤ pivot und i < rechts i := i + 1 ende // Suche von rechts ein Element, welches kleiner als das Pivotelement ist wiederhole solange daten[j] ≥ pivot und j > links j := j - 1 ende falls i < j dann tausche daten[i] mit daten[j] ende solange i < j // solange i an j nicht vorbeigelaufen ist // Tausche Pivotelement (daten[rechts]) mit neuer endgültiger Position (daten[i]) falls daten[i] > pivot dann tausche daten[i] mit daten[rechts] ende // gib die Position des Pivotelements zurück antworte i endeNach der Wahl des Pivotelementes wird zunächst ein Element vom Anfang der Liste beginnend gesucht (Index i), welches größer als das Pivotelement ist. Entsprechend wird vom Ende der Liste beginnend ein Element kleiner als das Pivotelement gesucht (Index j). Die beiden Elemente werden dann vertauscht und landen damit in der jeweils richtigen Teilliste. Dann werden die beiden Suchvorgänge von den erreichten Positionen fortgesetzt, bis sich die untere und obere Suche treffen; dort ist die Grenze zwischen den beiden Teillisten.
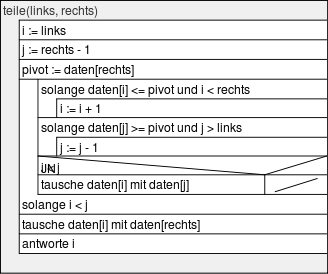
Struktogramm
Im folgenden ein Nassi-Shneiderman-Diagramm (Struktogramm) des Quicksort-Algorithmus. Die Bezeichner sind an obigen Pseudocode angelehnt worden.
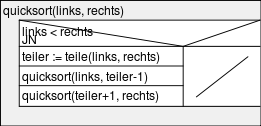
Beispiel
teile(links, rechts)Die Buchstabenfolge „einbeispiel“ soll alphabetisch sortiert werden.
Ausgangssituation nach Initialisierung von
iundj, das Element rechts (l) ist das Pivotelement:e i n b e i s p i e l ^ ^ i j
Nach der ersten Suche in den inneren Schleifen hat
iauf einem Element>= lund j auf einem Element<= lgehalten:e i n b e i s p i e l ^ ^ i jNach dem Tauschen der Elemente bei
iundj:e i e b e i s p i n l ^ ^ i jNach der nächsten Suche und Tauschen:
e i e b e i i p s n l ^ ^ i jNach einer weiteren Suche sind die Indizes aneinander vorbeigelaufen:
e i e b e i i p s n l ^ ^ j iNach dem Tauschen von
iund Pivot bezeichnetidie Trennstelle der Teillisten. Beiisteht das Pivot-Element, links davon sind nur Elemente<=Pivot und rechts nur solche>=Pivot:e i e b e i i l s n p ^ iVollständiges Beispiel für alphabetische Sortierung
In diesem Beispiel soll der Quicksortalgorithmus die Buchstabenfolge "Quicksort" sortieren. Zunächst wird das rechte Element
P->als Pivotelement definiert. Dann laufen die Zähler g für "größer" von links nach rechts und k für "kleiner" von rechts nach links los,Quicksort ^ ^^ g kP
bis g auf ein Element trifft, welches größer als das Pivotelement ist und bis k auf ein Element trifft, welches kleiner ist als das Pivotelement.
Quicksort ^ ^^ g kP
Diese beiden gefundenen Elemente r und u werden dann im folgenden Schritt getauscht.
Qricksout ^ ^^ g kP
Im folgenden Schritt laufen die Indizes k und g in der gleichen Richtung wie gehabt weiter und suchen Elemente, die bei k kleiner und bei g größer sind.
Qricksout ^^^ kgPJetzt sind k und g aneinander vorbeigelaufen. Dieses Ereignis ist eine Abbruchbedingung. Jetzt wird das Pivotelement mit dem durch g indizierten Element getauscht.
Qricksotu ^^^ kPgJetzt treffen folgende zwei Aussagen zu: "Links des Pivotelements sind alle Elemente kleiner als das Pivotelement. Rechts des Pivotelements sind alle Elemente größer als das Pivotelement."
links|:|rechts Qrickso|t|u ^|^|^ k|P|gDas Pivotelement "teilt" nun die Datenmenge an der Stelle des Pivotelements in zwei Hälften Links und Rechts. Nun muss der Algorithmus den linken und den rechten Teil auf die gleiche Weise wie im Vorangehenden schon geschehen weiterbehandeln. Hierdurch ergibt sich nun die Rekursion. Der rechte Teil (Der Buchstabe u) ist nur ein einzelnes Element und ist somit per Definition sortiert. Also wird nun der linke Teil behandelt. Das rechte Element ist wieder das Pivotelement, und die Zähler werden passend gesetzt.
Qrickso|t|u ^ ^^ g kP
Das Q ist größer als o und das k ist kleiner als das o.
Qrickso|t|u ^ ^ ^ g k P
Also werden das Q und das k vertauscht.
kricQso|t|u ^ ^ ^ g k P
Indizes g und k laufen weiter...
kricQso|t|u ^ ^ ^ g k P
Das r und das c werden getauscht.
kcirQso|t|u ^ ^ ^ g k P
Im folgenden Schritt sind die Indizes wieder aneinander vorbeigelaufen...
kcirQso|t|u ^^ ^ kg P
... und das Pivotelement (Buchstabe o) wird mit dem größeren Element (Buchstabe r) getauscht.
kcioQsr|t|u ^^ ^ kP g
Nun ergibt sich erneut ein linker und ein rechter Teil.
links:rechts kci|o|Qsr |t|u ^|^| ^ | | k|P| g | |
Zunächst wird der linke Teil behandelt.
: kci|o| Qsr|t|u ^ ^^| |^ ^^| | g kP| |g kP| |: cki|o| Qsr|t|u ^^^| |^ ^^| | gkP| |g kP| |Buchstabe c und k werden getauscht.
: cki|o| Qsr|t|u ^^^| |^ ^^| | kgP| |g kP| |Indizes sind aneinander vorbeigelaufen, und das Element des Index g wird mit dem des Index P vertauscht.
: cik|o| Qsr|t|u ^^^| |^ ^^| | kPg| |g kP| |Der jetzt entstandene neue linke und rechte Teil besteht nun nur noch aus einem einzelnen Element und gilt als sortiert.
: cik|o| Qsr|t|u | | ^^^| | | | kgP| |Im ehemals rechten Teil (Buchstaben Qsr) laufen die Indizes direkt aneinander vorbei, und das Element bei g wird mit dem Pivotelement getauscht.
: cik|o| Qrs|t|u | | ^^^| | | | kPg| |Damit sind alle Zeichen sortiert.
cik|o| Qrs|t|u
Ergebnis: cikoQrstu
Kenngrößen
Laufzeit
Die Laufzeit des Algorithmus hängt im Wesentlichen von der Wahl des Pivotelementes ab.
Im Worst Case (schlechtesten Fall) wird das Pivotelement stets so gewählt, dass es das größte oder das kleinste Element der Liste ist. Dies ist etwa der Fall, wenn als Pivotelement stets das Element am Ende der Liste gewählt wird und die zu sortierende Liste bereits sortiert vorliegt. Die zu untersuchende Liste wird dann in jedem Rekursionsschritt nur um eins kleiner und die Zeitkomplexität wird beschrieben durch
 .
.Im Best Case (bester Fall) wird das Pivotelement stets so gewählt, dass die beiden entstehenden Teillisten etwa gleich groß sind. In diesem Fall gilt für die asymptotische Laufzeit des Algorithmus
 . Diese Zeitkomplexität gilt ebenso für den Average Case (durchschnittlichen Fall), bei dem die Längen der Teillisten jeweils durchschnittlich
. Diese Zeitkomplexität gilt ebenso für den Average Case (durchschnittlichen Fall), bei dem die Längen der Teillisten jeweils durchschnittlich  betragen.
betragen.Für die Wahl des Pivotelementes sind in der Literatur verschiedene Ansätze beschrieben worden. Die Wahrscheinlichkeit des Eintreffens des Worst Case ist bei diesen unterschiedlich groß.
Ein möglicher Ansatz ist es, immer das erste, das letzte oder das mittlere Element der Liste zu wählen. Dieser naive Ansatz ist aber relativ ineffizient. Eine andere Möglichkeit ist es den Median dieser drei Elemente zu bestimmen und als Pivotelement zu verwenden. Ein anderer Ansatz ist, als Pivotelement ein zufälliges Element auszuwählen. Bei diesem randomisierten Quicksort ist die Wahrscheinlichkeit, dass das Pivotelement in jedem Teilungsschritt so gewählt wird, dass sich die Worst-Case-Laufzeit ergibt, extrem gering. Man kann davon ausgehen, dass er praktisch nie auftritt.
Es gibt Algorithmen, beispielsweise Heapsort, deren Laufzeit auch im Worst Case durch
beschränkt sind. In der Praxis wird aber trotzdem Quicksort eingesetzt, da angenommen wird, dass bei Quicksort der Worst Case nur sehr selten auftritt und im mittleren Fall schneller als Heapsort ist, da die innerste Schleife von Quicksort nur einige wenige, sehr einfache Operationen enthält. Dies ist jedoch noch Forschungsgegenstand und einige Analysen und Simulationen sehen Heapsortvarianten vorne, sowohl aus informationstheoretischen Überlegungen wie Implementierungsbetrachtungen.[2][3]Heute ist Quicksort für ein breites Spektrum von praktischen Anwendungen der bevorzugte Sortieralgorithmus, weil er schnell ist und, sofern Rekursion zur Verfügung steht, einfach zu implementieren ist. In vielen Standardbibliotheken ist er bereits vorhanden. Mittlerweile steht jedoch mit Introsort auch eine Alternative zur Verfügung, die bei vergleichbarer mittlerer Laufzeit auch für den Worst Case eine obere Schranke von
garantiert.Speicherplatz
Quicksort ist kein in-Place-Verfahren. Es vertauscht zwar die Elemente der zu sortierenden Liste nur innerhalb der Liste und kopiert sie nicht in zusätzlichen Speicherplatz. Es benötigt jedoch für jede Rekursionsebene zusätzlichen Platz auf dem Stack.
Wie bei der Laufzeit hängt auch der Speicherverbrauch von der Wahl des Pivotelements und der Art der vorliegenden Daten ab. Im günstigsten und durchschnittlichen Fall, bei einer Rekursionstiefe in
 , wird auch nur eine Stapelgröße von benötigt.
, wird auch nur eine Stapelgröße von benötigt.Im ungünstigsten Fall ist die Anzahl der Rekursionen nur durch die Listenlänge n beschränkt, was einen Stapel der Größe
 erfordert. Dies kann bei langen Listen zu einem Stapelüberlauf führen. Es gibt vielfältige Modifikationen des Algorithmus um dieses Problem zu lösen oder zumindest die Wahrscheinlichkeit seines Auftretens zu vermindern[4]:
erfordert. Dies kann bei langen Listen zu einem Stapelüberlauf führen. Es gibt vielfältige Modifikationen des Algorithmus um dieses Problem zu lösen oder zumindest die Wahrscheinlichkeit seines Auftretens zu vermindern[4]:- Endrekursionsbeseitigung (siehe nachfolgenden Pseudocode)
- eine ausgewogenere Wahl des Pivotelements (z. B. Median von Drei)
- Wahl eines zufälligen Pivotelements, wodurch systematische Probleme vermieden werden, die sich sonst durch bestimmte Vorsortierungen der Elemente im Zusammenspiel mit der Methode der Pivotwahl ergeben können
- Vermeidung von Teillisten mit weniger als zwei Elementen (ergibt, wenn auch das Pivotelement aus den Teillisten genommen wird, die maximale Rekursionstiefe n / 3)
Der folgende Pseudocode ersetzt die Endrekursion (Sortierung der zweiten Teilliste) durch eine Iteration derart, dass die kürzere Teilliste rekursiv und die längere iterativ sortiert wird. Die Rekursionstiefe ist dann nicht größer als log(n):
funktion quicksort(links, rechts) solange rechts > links wiederhole teiler := teile (links, rechts) falls rechts-teiler > teiler-links quicksort(links, teiler - 1) // kleinere Teilliste rekursiv .. links := teiler + 1 // .. und größere iterativ sortieren sonst quicksort(teiler + 1, rechts) rechts := teiler - 1 ende ende endeEine weitere Möglichkeit den in n linearen zusätzlichen Speicherplatz zu vermeiden besteht darin, dass man zuerst die kleinere der beiden Teilfolgen rekursiv sortiert (die andere wird danach sortiert, aber ebenfalls rekursiv). Somit bleibt die Anzahl der noch nicht sortierten Teilfolgen durch
 beschränkt. Für jede noch nicht sortierte Teilfolge werden zwei Indexgrenzen gespeichert, die jeweils zusätzlichen Speicherplatz benötigen. Insgesamt benötigt Quicksort mit dieser Variante
beschränkt. Für jede noch nicht sortierte Teilfolge werden zwei Indexgrenzen gespeichert, die jeweils zusätzlichen Speicherplatz benötigen. Insgesamt benötigt Quicksort mit dieser Variante  zusätzlichen Speicherplatz im logarithmischen Kostenmaß.
zusätzlichen Speicherplatz im logarithmischen Kostenmaß.Varianten
Bei nachfolgend dargestellter QuickSort-Variante für verkettete Listen wird als Pivotelement das jeweils erste der zu teilenden Folge gewählt. Ein Zeiger Ptr2 wird soweit vorgeschoben, bis er auf ein Element trifft, das kleiner als das Pivot ist. Die Elemente, über die Ptr2 hinweggegangen ist, sind demzufolge größer oder gleich dem Pivot. Ein Tausch des ersten dieser größeren Elemente mit dem bei Ptr2 sorgt also dafür, dass die betreffenden Elemente im richtigen Teilabschnitt landen. Ptr1 markiert das aktuelle Ende des Teilabschnitts der Elemente, die kleiner als das Pivot sind. Wenn Ptr2 am rechten Rand der zu teilenden Folge angelangt ist, wird abschließend das Pivotelement an die richtige Position zwischen den Teilfolgen getauscht.
QuickSort(Links,Rechts); //Links, Rechts sind hier Zeiger falls Links<>Rechts dann Ptr1:=Links Ptr2:=Links Ptr0:=Links //Initialisierung der (lokalen) Zeiger; Ptr0 wird nur als Vorgänger von Ptr1 benötigt Pivot:=Links.Zahl wiederhole Ptr2:=Ptr2.Nachfolger; falls Ptr2.Zahl<Pivot dann Ptr0:=Ptr1; Ptr1:=Ptr1.Nachfolger; tausche(Ptr1,Ptr2) solange bis Ptr2=Rechts; tausche(Links,Ptr1) falls Ptr1<>Rechts dann Ptr1:=Ptr1.Nachfolger; QuickSort(Links,Ptr0); QuickSort(Ptr1,Rechts) ende
Der Nachteil dieses Verfahrens liegt darin, dass weitgehend sortierte Folge oder viele gleichartige Schlüsselwerte zu einem Worst-Case-ähnlichen Verhalten führen. Daher wählt man für verkettete Listen gern Sortieralgorithmen wie etwa Mergesort, die auch im Worst Case eine Zeitkomplexität von
 besitzen. Andere dynamische Datenstrukturen wie balancierte Bäume (z. B. B-Bäume, AVL-Bäume) verteilen die Kosten des Sortierens auf die Einfügeoperationen, so dass nachträgliches Sortieren nicht notwendig ist.
besitzen. Andere dynamische Datenstrukturen wie balancierte Bäume (z. B. B-Bäume, AVL-Bäume) verteilen die Kosten des Sortierens auf die Einfügeoperationen, so dass nachträgliches Sortieren nicht notwendig ist.Iteratives Quicksort
Quicksort kann auch nicht-rekursiv mit Hilfe eines kleinen Stack oder Array implementiert werden. Hier eine einfache Variante mit zufälliger Auswahl des Pivotelements:
funktion quicksort_iterativ(links, rechts) wiederhole // äußere Schleife falls links < rechts dann pivot := daten[random(links, rechts)] // Auswahl eines zufälligen Elements i := links-1 j := rechts+1 wiederhole // innere Schleife, teile Feld wiederhole i := i+1 solange daten[i] < pivot wiederhole j := j-1 solange daten[j] > pivot falls i >= j dann Abbruch innere Schleife tausche daten[i], daten[j] ende push (rechts) // rechten Teil später sortieren rechts := max(links, i-1) // jetzt linken Teil sortieren sonst // linker Teil sortiert falls stapel leer dann Abbruch äußere Schleife // noch ein rechter Teil übrig ? links := rechts+1 pop (rechts) // jetzt rechten Teil sortieren ende ende ende
Die Anweisung
pushlegt dabei ein Element auf den Stack wo es mitpopwieder geholt wird. Die Größe des nötigen Stapelspeichers ist dabei mit ausreichender Sicherheit kleiner als 5·log2(n)/3.Die Effizienz von Quicksort liegt darin, dass es Elemente aus großer Distanz miteinander vertauscht. Je kürzer die zu sortierende Liste wird, desto ineffizienter arbeitet Quicksort, da es sich einer Komplexität von
nähert. Die von Quicksort in Teillisten zerlegte Liste hat jedoch die Eigenschaft, dass der Abstand zwischen einem Element und seiner sortierten Position nach oben beschränkt ist. Eine solche Liste sortiert Insertionsort in linearer Zeit, so dass häufig in der Implementierung unterhalb einer definierten Teillistenlänge der Quicksort abgebrochen wird, um mit Insertionsort weiter zu sortieren.Einzelnachweise
- ↑ C. A. R. Hoare: Quicksort. Computer Journal, Vol. 5, 1, 10–15 (1962)
- ↑ Paul Hsieh (2004): Sorting revisited.. www.azillionmonkeys.com. Abgerufen am 26. April 2010.
- ↑ David MacKay (1. Dezember 2005): Heapsort, Quicksort, and Entropy. www.aims.ac.za/~mackay. Archiviert vom Original am 7. Juni 2007. Abgerufen am 26. April 2010.
- ↑ Ellis Horowitz, Sartaj Sahni, Susan Anderson-Freed: Grundlagen von Datenstrukturen in C. 1. Auflage. International Thomson Publishing, 1994, ISBN 3-929821-00-1, S. 342.
Literatur
- Robert Sedgewick: Algorithmen. Pearson Studium 2002 ISBN 3827370329
- Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, Clifford Stein: Introduction to Algorithms. 2. Auflage. MIT Press, Cambridge (Massachusetts) 2001, ISBN 0-262-03293-7 (ein Standardwerk zu Algorithmen).
- Thomas H Cormen, Charles E. Leiserson, Ronald L. Rivest, Clifford Stein: Algorithmen – eine Einführung. 2., korr. Auflage. Oldenbourg, München, Wien 2007, ISBN 3-486-58262-3.
Weblinks




Wikimedia Foundation.